
Cascateamento de redo em uma configuração Data Guard
Em algumas configurações Data Guard, podemos encontrar cenários onde os bancos standby estão geograficamente distantes do banco primário. Neste tipo de cenário, podemos ter uma sobrecarga no banco primário, pelo envio de redo para bases distantes, e também pela utilização de banda de rede.
Visando reduzir a carga no banco primário, podemos adotar a estratégia de cascateamento de redo, onde o banco primário envia o redo para o standby mais próximo, e este por sua vez faz o envio do redo recebido do banco primário para os demais standbys. Esse standby que envia redo para outros standby recebe o nome de cascading standby.
A estratégia de cascateamento de redo é bastante similar ao uso de uma instância Far Sync, porém no caso do cascateamento, o banco standby que replica o redo para os outros bancos pode ser o alvo de um switchover ou failover, possibilidade que não existe em instâncias Far Sync.
Cascateamento de redo: conceitos importantes
O banco cascading standby pode replicar o redo para os outros standbys em real-time, ou seja, enquanto aplica o redo nos seus standby redo log files, ou non-real-time, onde fará o envio dos dados de redo após arquivar os standby redo logs.
Algumas considerações sobre o cascateamento:
- Apenas standbys físicos podem cascatear redo;
- Para o cascateamento real-time é necessário ter uma licença Active Data Guard;
- O cascateamento non-real-time é suportado apenas nos destinos (LOG_ARCHIVE_DEST_n) de 1 a 10;
Os bancos que recebem o redo de um cascading standby são chamados de destinos terminais.
Exemplo de cascateamento de redo
Suponhamos que temos os seguintes bancos em uma configuração Data Guard:
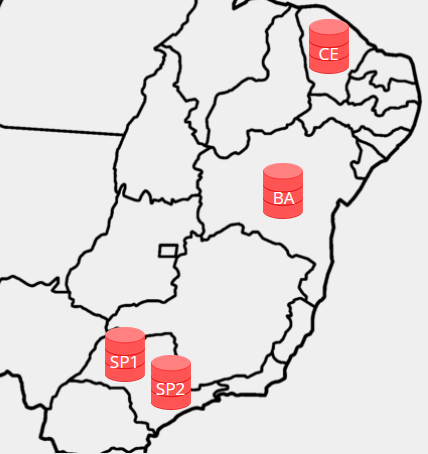
Onde:
- SP1: é o banco primário e tem o DB_UNIQUE_NAME de “saopaulo1”;
- SP2: é o cascading standby e tem o DB_UNIQUE_NAME de “saopaulo2”;
- BA e CE: são os destinos terminais, que receberão o redo do cascading standby, e tem o DB_UNIQUE_NAME de “bahia” e “ceara”;
- Todos os bancos são tem o DB_NAME “orcl”;
- Todos os bancos, exceto “saopaulo1”, são standbys físicos;
- Neste cenário, apenas os bancos de São Paulo podem atuar como primários, sendo que em um dado momento, um é o banco primário e o outro o cascading standby.
Para que o cascateamento ocorra, devemos configurar o banco primário com os seguintes parâmetros:
log_archive_config='DG_CONFIG=(SAOPAULO1, SAOPAULO2, BAHIA, CEARA)' fal_server=SAOPAULO2 log_archive_dest_1='LOCATION=USE_DB_RECOVERY_FILE_DEST VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=SAOPAULO1' ALTER SYSTEM SET log_archive_dest_2='SERVICE=SAOPAULO2 ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=SAOPAULO2' log_archive_dest_3='SERVICE=BAHIA ASYNC VALID_FOR=(STANDBY_LOGFILES,STANDBY_ROLE) DB_UNIQUE_NAME=BAHIA' log_archive_dest_4='SERVICE=CEARA ASYNC VALID_FOR=(STANDBY_LOGFILES,STANDBY_ROLE) DB_UNIQUE_NAME=CEARA'
Neste cenário, configuramos o LOG_ARCHIVE_DEST_2 apontando para o cascading standby. Em VALID_FOR especificamos que o envio será feito somente quando o banco estiver na role primária e estiver arquivando os online log files.
Também configuramos os parâmetros LOG_ARCHIVE_DEST_3 e LOG_ARCHIVE_DEST_4, apontando para os destinos terminais, para que, quando este banco assumir a role standby no caso de failover ou switchover, ele passe a enviar os dados de redo recebidos do novo primário para estes bancos. Tal comportamento é configurado no parâmentro VALID_FOR, com os valores STANDBY_LOGFILES e STANDBY_ROLE, e é ele que faz com que o standby faça o cascateamento de redo para outros standby.
A configuração do cascading standby SAOPAULO2 é bastante semelhante:
log_archive_config='DG_CONFIG=(SAOPAULO1, SAOPAULO2, BAHIA, CEARA)' fal_server=SAOPAULO1 log_archive_dest_1='LOCATION=USE_DB_RECOVERY_FILE_DEST VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=SAOPAULO2' log_archive_dest_2='SERVICE=SAOPAULO1 ASYNC VALID_FOR=(ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME=SAOPAULO1' log_archive_dest_3='SERVICE=BAHIA ASYNC VALID_FOR=(STANDBY_LOGFILES,STANDBY_ROLE) DB_UNIQUE_NAME=BAHIA' ALTER SYSTEM SET log_archive_dest_4='SERVICE=CEARA ASYNC VALID_FOR=(STANDBY_LOGFILES,STANDBY_ROLE) DB_UNIQUE_NAME=CEARA' SCOPE=SPFILE SID='*';
Neste banco, configuramos o parâmetro LOG_ARCHIVE_DEST_2 apontando para o banco SAOPAULO1, para que quando o banco SAOPAULO2 assuma a role primária, ele faça o envio de redo para este banco, que por sua vez fará o cascateamento.
Como este banco está com a role standby, e arquivando standby redo log files, os destinos configurados em LOG_ARCHIVE_DEST_3 e LOG_ARCHIVE_DEST_4 estão ativos, e recebem o redo através deste banco.
Já a configuração dos destinos terminais de redo desta configuração são mais simples. No banco BAHIA temos:
log_archive_config='DG_CONFIG=(SAOPAULO1, SAOPAULO2, BAHIA, CEARA)' fal_server=SAOPAULO2 log_archive_dest_1='LOCATION=USE_DB_RECOVERY_FILE_DEST VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=BAHIA'
E no banco CEARA temos:
log_archive_config='DG_CONFIG=(SAOPAULO1, SAOPAULO2, BAHIA, CEARA)' fal_server=SAOPAULO2 log_archive_dest_1='LOCATION=USE_DB_RECOVERY_FILE_DEST VALID_FOR=(ALL_LOGFILES,ALL_ROLES) DB_UNIQUE_NAME=CEARA'
Para estes bancos apenas é configurado o FAL_SERVER, que aponta para o banco onde o standby atual buscará por redo não recebido, e onde serão arquivados os dados de redo do banco, definido no parâmetro LOG_ARCHIVE_DEST_1.
Coletando informações sobre uma configuração Data Guard com cascateamento
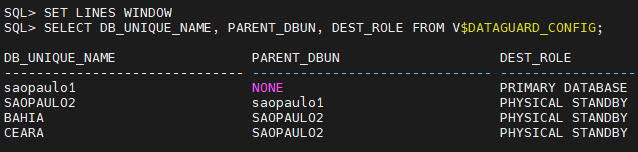
Caso seja necessário identificar as fontes de redo de cada banco, podemos utilizar a view V$DATAGUARD_CONFIG. A view trás a coluna PARENT_DBUN, que especifica o DB_UNIQUE_NAME do banco que fornece redo para o destino, e a coluna DEST_ROLE, que especifica o tipo de cada destino de redo.
Para o exemplo citado acima, uma query nesta view retorna o seguinte:
Conclusão
Configurações Data Guard podem ir muito além de apenas um banco primário e um banco standby, e neste artigo meu objetivo foi trazer um cenário abordando o conceito de cascateamento de redo.
Espero que este artigo tenha te ajudado a compreender este conceito.
Publicar comentário