
Criação de tabelas para estudo de Oracle SQL com Python e SQL Developer
Nas aulas de SQL que tenho ministrado, um dos pontos mais trabalhosos sempre foi a criação de dados teste, para que os alunos pudessem colocar a mão na massa, aplicando os conceitos aprendidos durante as aulas.
O cenário melhorou bastante com a utilização do ChatGPT, que consegue auxiliar na elaboração de cenários que contextualizam os conceitos abordados em situações reais. Ainda assim, a criação dos dados a partir do ChatGPT é complicada, devido ao limite de linhas geradas por prompt, e à velocidade de geração do mesmo.
Felizmente, encontrei um artigo do Lorran Borges na minha timeline do LinkedIn, que me apresentou à package Faker do Python (vou deixar o link para o artigo dele ao fim deste artigo).
Conhecendo a Faker
A package Faker serve para geração de dados “fake”, ou seja, dados fictícios para teste. O que chama atenção dessa package é que ela permite a geração de dados localizados. Podemos gerar dados com nomes brasileiros, caso seja repassada a localidade “pt_BR” para a package. Inclusive o nome de estados, cidade, pessoas, entre outros, são gerados pela package.
Além disso a package consegue gerar dados de data e hora, moedas, CPF, RG, email, telefone, IP, profissões, e muito mais.
Código para geração de dados
O código Python utilizado aqui é uma adaptação do código original postado pelo Lorran, portanto acessem o artigo dele!
import csv
from faker import Faker
from unidecode import unidecode
# Instância do Faker com código pt_BR que é o idioma Português
fake = Faker('pt_BR')
# Geração dos dados
dados = []
for i in range(500):
registro = {
'id': i + 1,
'nome': unidecode(fake.name()),
'endereco': unidecode(fake.address().replace('\n', ' ')),
'data': fake.date_time().strftime('%d/%m/%y %H:%M:%S'),
'email': fake.email(),
'telefone': fake.phone_number(),
}
dados.append(registro)
# Escrevendo os registros no arquivo CSV
dados_csv = 'dados.csv'
with open(dados_csv, mode='w', newline='') as arquivo_csv:
header = ['id', 'nome', 'data', 'endereco', 'email', 'telefone']
escritor_csv = csv.DictWriter(arquivo_csv, fieldnames=header)
escritor_csv.writeheader()
for registro in dados:
escritor_csv.writerow(registro)
O código acima gera 500 registros para uma tabela, com as colunas “id”, “nome”, “endereco”, “data”, “email” e “telefone”, cujos valores são gerados pelo Faker.
Nesse código estou utilizando a package unidecode para retirar as acentuações dos nomes e endereços gerados.
Após a geração os dados são escritos para um arquivo CSV, o qual será utilizado para a importação no SQL Developer.
Criando uma tabela a partir de um arquivo CSV no SQL Developer
Com a sessão iniciada no SQL Developer, clicamos com o botão direito e selecionamos “Importar Dados”:
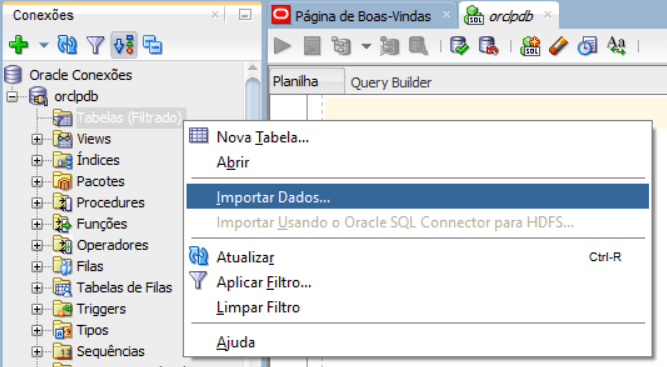
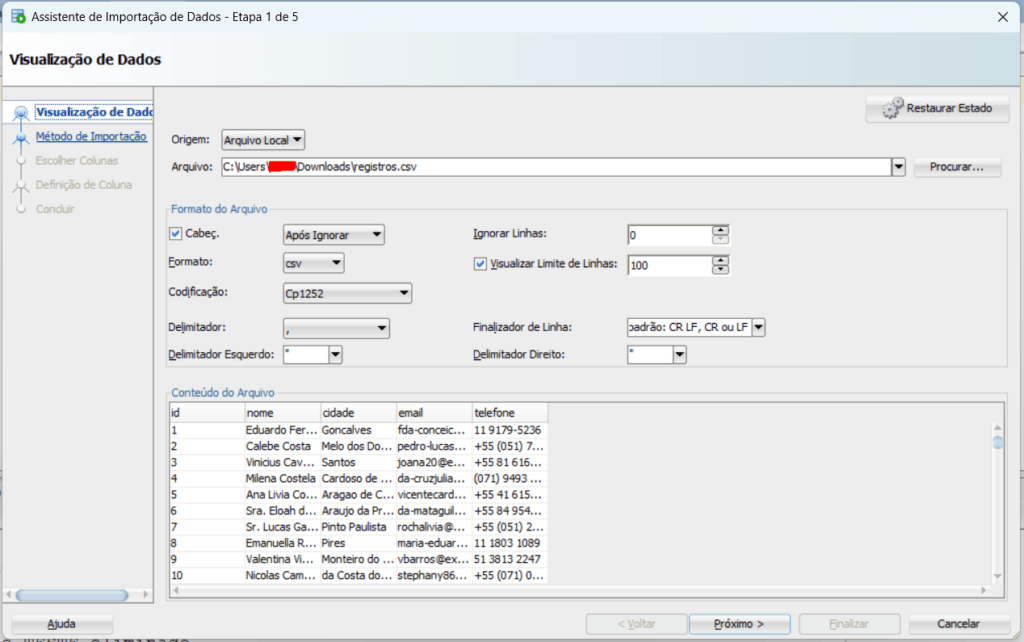
Na tela seguinte selecionamos o nosso arquivo CSV gerado pelo código Python e ajustamos as opções de formato do arquivo:
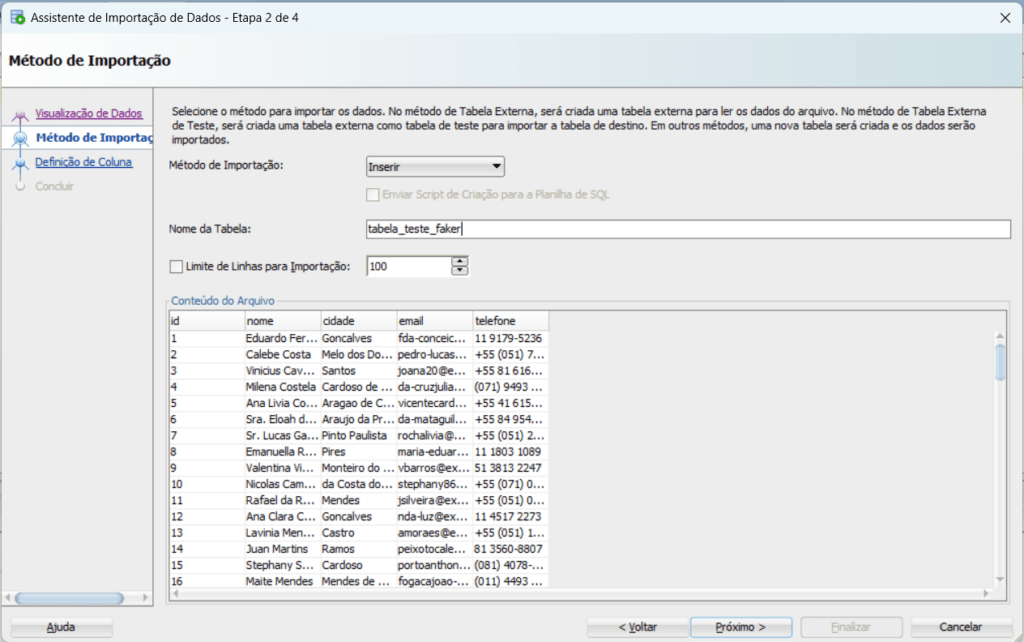
Em seguida selecionamos o método de importação e damos um nome à tabela que irá comportar os dados contidos no CSV:
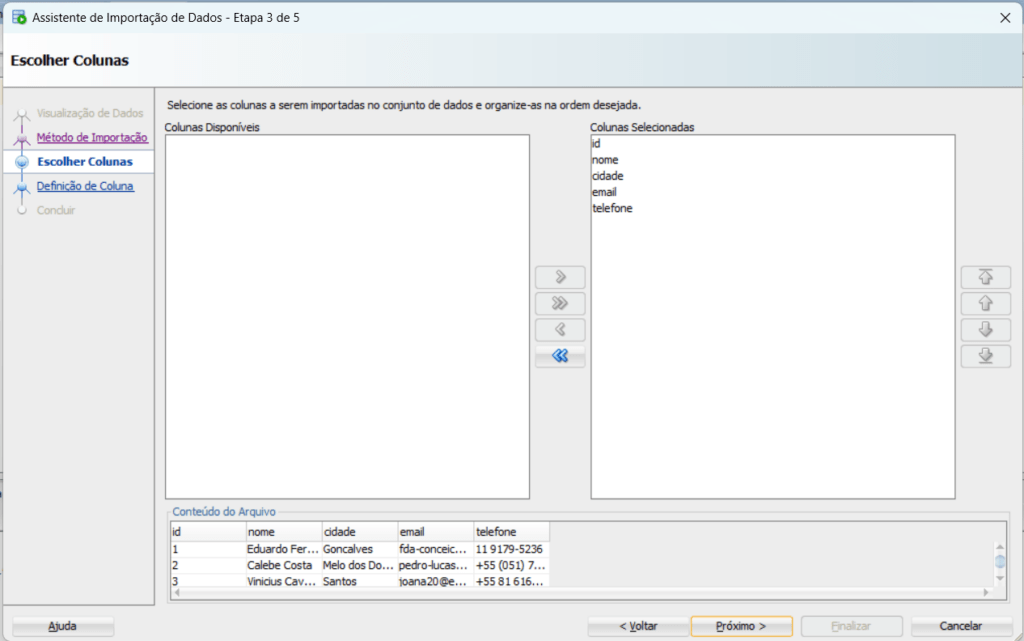
No próximo passo, podemos selecionar quais colunas devem ser importadas:
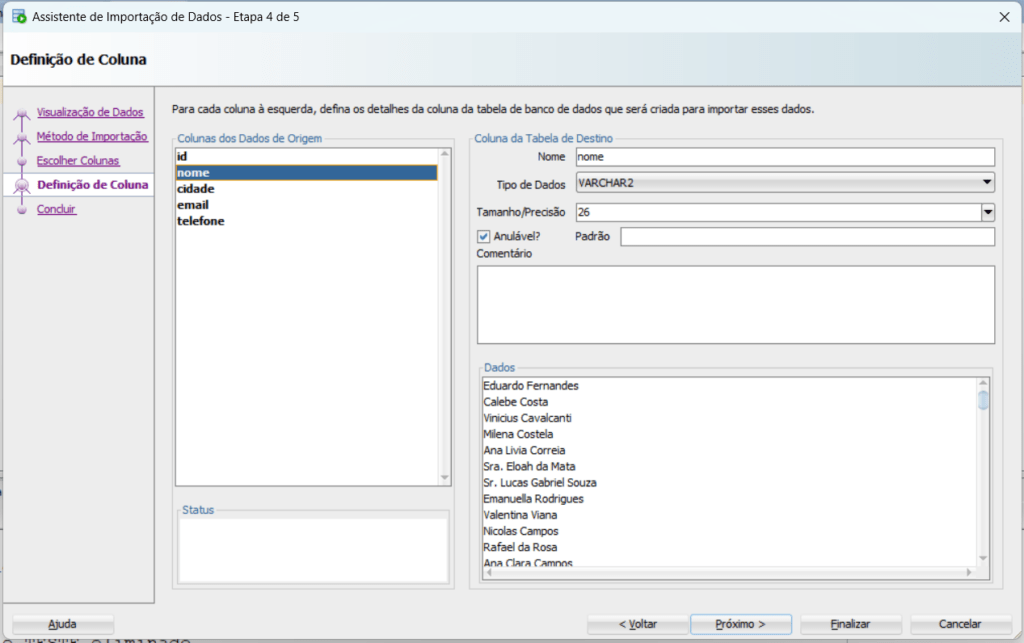
Por fim, podemos editar o tipo de dado que cada coluna terá, bem como sua precisão e escala, no caso de tipos numéricos, ou o tamanho, no caso de texto:
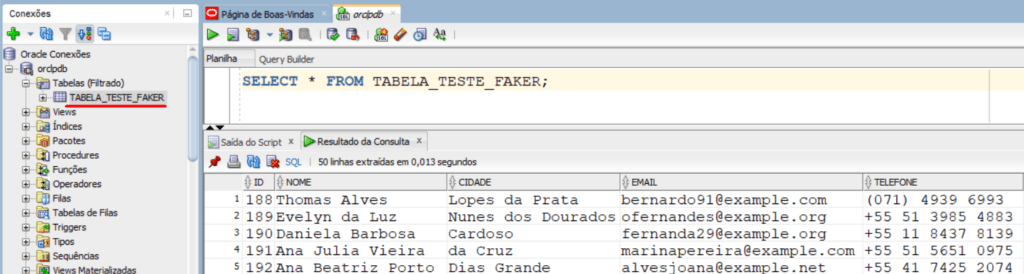
Após a conclusão da importação a tabela já está disponível para utilização e aplicação dos conceitos SQL:
Conclusão
A linguagem Python, juntamente com a package Faker, proporciona uma forma bastante ágil para a criação de dados de teste, o que ajuda muito na criação de exemplos para o aprendizado de SQL.
Abaixo segue o artigo do Lorran que usei como base para a geração do código Python disponibilizado:
Gerando Dados Fictícios com Python – Lorran Borges
Um grande abraço a todos!
Publicar comentário