
Utilização de Índices Compostos no Oracle Database
Quando falamos em melhoria de performance de consultas SQL, um dos primeiros assuntos que nos vem à cabeça são os índices. Essas estruturas nos fornecem uma forma de melhorar o acesso aos dados armazenados em tabelas do nosso banco de dados, diminuindo a quantidade de dados a serem escaneados pelo nosso SGBD. Para isso, os índices armazenam parcelas dos dados das tabelas, chamados chaves dos índices, juntamente com o endereço da linha desses dados nos arquivos dados da tabela, ocupando assim um espaço adicional em disco, em troca de um ganho de performance nas consultas.
No Oracle, assim como em outros SGBD’s, o índice mais comum é o índice B-Tree (balanced tree), que armazena os valores das chaves dos índices e seu endereçamento em uma estrutura de árvore, sendo composta pelos branch blocks (blocos galho), que são usados para encontrar os leaf blocks (blocos folha), estes contendo o endereço da linha em disco, o rowid:
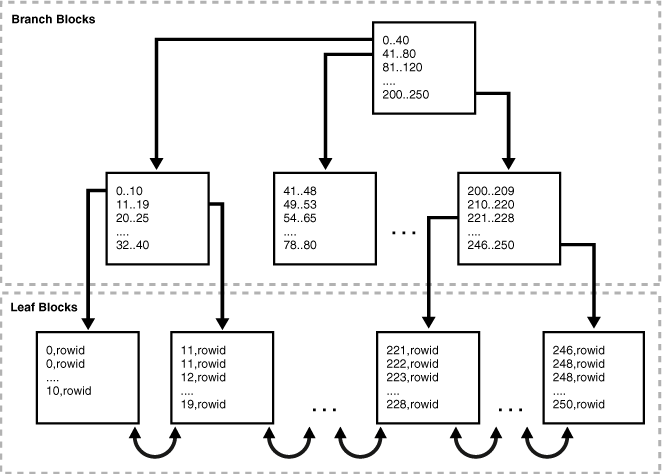
Fonte: Oracle
Os leaf blocks apontam para o próximo bloco, em uma estrutura de lista encadeada, a fim de que em uma situação de leitura de um intervalo de valores que esteja além de um leaf block, o SGBD conheça o endereço do leaf block seguinte, e não precise recalcular todo o trajeto através dos branch blocks.
Podemos classificar os índices de acordo com o número de colunas que compõem a chave do índice:
- Índices Simples: aqueles onde apenas uma coluna é indexada. Por exemplo:
CREATE INDEX idx_simples ON employees (employee_id);
Índices Compostos: aqueles onde duas ou mais colunas são indexadas. Por exemplo:
CREATE INDEX idx_composto ON employees (employee_id, first_name);
A utilização de índices compostos deve ser levada em consideração quando diversas colunas de tabelas são acessadas frequentemente na mesma consulta. Eles podem acelerar consultas que filtram a consulta com base em todas as colunas indexadas ou parte delas. Neste ponto é que as coisas começam a ficar interessantes.Considerações referentes à performance
Na criação de índices compostos a ordem das colunas afeta diretamente o impacto do índice na performance da consulta. A coluna que mais filtra a consulta dentro da cláusula WHERE deve ser especificada antes, facilitando o acesso do SGBD aos níveis posteriores do índice.
Vamos ao exemplo:
Considerando uma tabela chamada “employees”, com a seguinte estrutura:
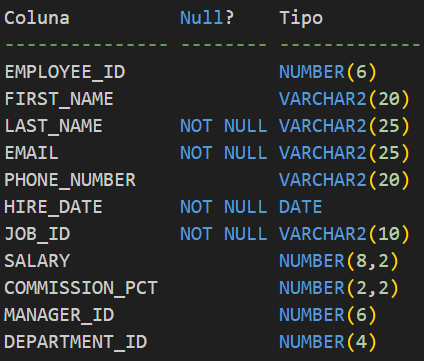
Nesta tabela, criamos um índice composto indexando as colunas EMPLOYEE_ID e FIRST_NAME:
CREATE INDEX idx_id_name ON employees (employee_id, first_name);
Um exemplo de consulta que utilizaria este índice seria:
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES WHERE EMPLOYEE_ID = 145 AND FIRST_NAME = 'John';
Podemos verificar o plano de execução da consulta:
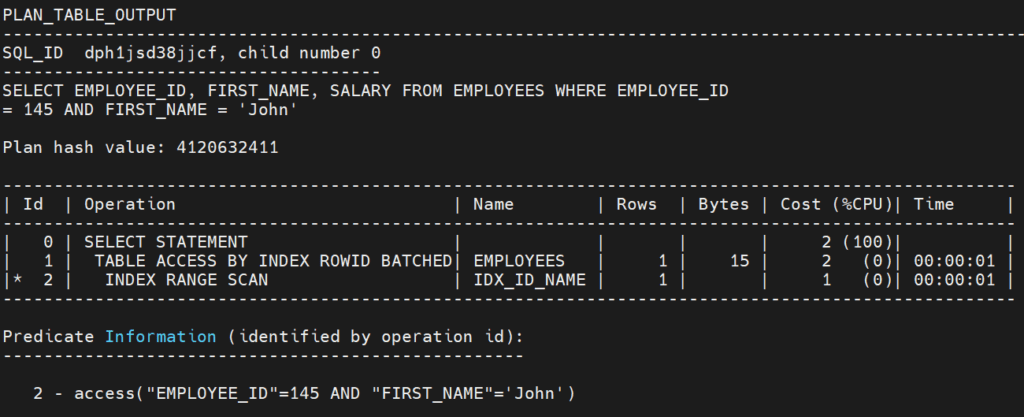
Neste caso, podemos verificar a execução de um INDEX RANGE SCAN, mostrando que houve um acesso ao índice criado anteriormente. Isso se deve ao fato de que ambas as colunas que estão sendo indexadas pelo índice foram usadas na filtragem da consulta.
Em alguns SGBD’s, caso a ordem das colunas do índice não corresponda às colunas que estão filtrando a consulta, o índice é automaticamente ignorado, não sendo levado em consideração para o plano de execução.
Já no Oracle, a partir da versão 9i, a funcionalidade de Index Skip Scan foi implementada, permitindo que mesmo que as primeiras colunas indexadas não sejam utilizadas na consulta, o índice possa ser utilizado.
Vejamos a query abaixo:
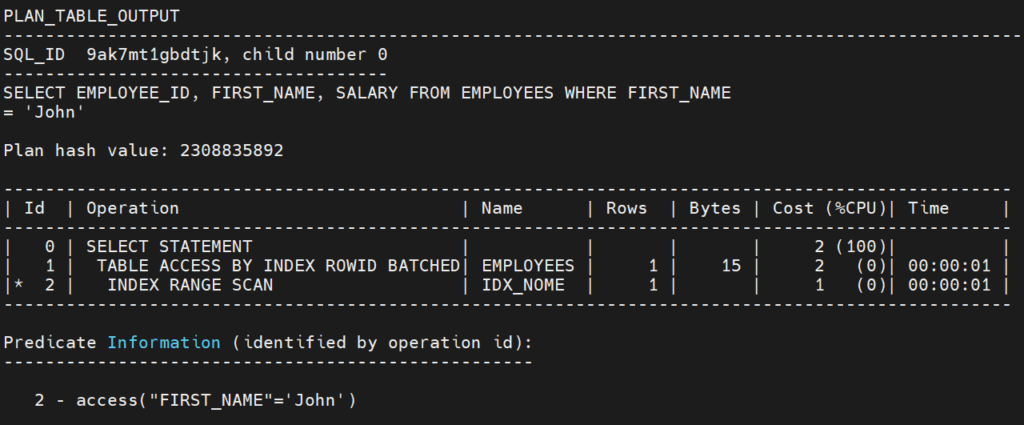
SELECT EMPLOYEE_ID, FIRST_NAME, SALARY FROM EMPLOYEES WHERE FIRST_NAME = 'John';
Nesse caso, apenas a segunda coluna do nosso índice está sendo utilizada na filtragem dos dados. No plano de execução temos um INDEX SKIP SCAN no lugar do nosso INDEX RANGE SCAN:
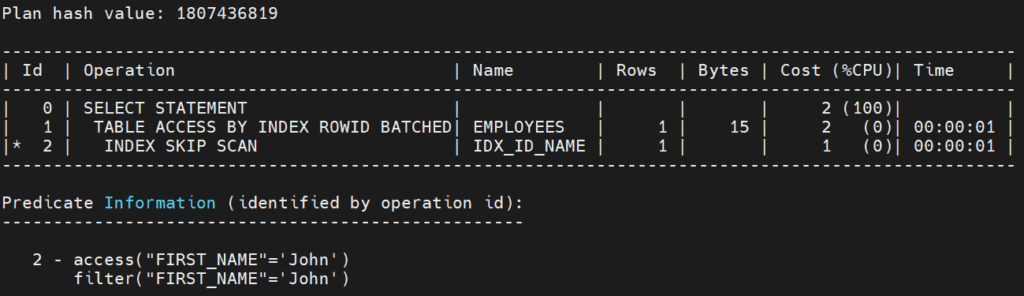
Nesse cenário, o Oracle “skipa” a primeira coluna, e analisa o índice como se ele fosse um conjunto de sub índices lógicos. Esse tipo de acesso pode ser benéfico em situações onde temos poucos valores distintos na primeira coluna do índice e vários valores distintos nas demais colunas, pois essa distribuição gera poucos sub índices.
Na nossa tabela employees essa situação não ocorre, pois a coluna EMPLOYEE_ID possui valores distintos. Nesse cenário, caso um índice específico para a coluna FIRST_NAME seja criado, ele será utilizado para a consulta, evitando o overhead de análise de cada sub índice:
CREATE INDEX idx_nome ON employees(first_name);
Para estes cenários entretanto, é necessário avaliar o impacto de utilização de armazenamento e o overhead da manutenção do índice pelo banco de dados. Dependendo do cenário, a criação de um índice adicional se torna inviável, e o melhor custo benefício é manter o INDEX SKIP SCAN acontecendo.
Outro ponto interessante da utilização de índices compostos, é a possibilidade do índice suprir todos os dados solicitados pela consulta, caso as colunas solicitadas estejam indexadas.
No exemplo anterior, no ID 1 do nosso plano de execução, existe um TABLE ACCESS BY ROWID, onde o SGBD usa o rowid obtido a partir do INDEX RANGE SCAN para encontrar os demais dados na tabela. No caso da nossa consulta, estamos buscando também os dados da coluna SALARY, que não está indexada. Podemos eliminar esse acesso à tabela, através de um índice composto que contenha as três colunas envolvidas na query:
CREATE INDEX idx_id_nome_salario ON employees (employee_id, first_name, salary);

Aqui novamente vale ressaltar que apesar no ganho de performance em relação à extinção do acesso à tabela, teremos um índice que precisará comportar mais dados e consequentemente terá um overhead maior de manutenção pelo banco de dados.
Concluindo
Embora tenhamos diversos benefícios com a criação de índices, precisamos ter o cuidado de não criar índices demais, pois isso pode prejudicar a performance do banco. Antes da implementação dessas melhorias, o ideal é realizar diversos testes em ambientes de desenvolvimento para medir os impactos das mesmas.
Lembre-se: a diferença entre o remédio e o veneno é a dose.
Espero que tenham aprendido algo novo. Grande abraço!
Publicar comentário