
Log File Sync: causas e soluções
A análise de wait events é um ponto importante para a identificação dos problemas que afetam a performance do banco de dados Oracle. Recentemente durante uma análise de performance, identifiquei que o wait event Log File Sync estava em evidência no banco de dados analisado, o que parecia ser o principal fator impactando o ambiente. Aqui vamos explorar as principais causas e possíveis soluções desse wait event, e também vou citar qual foi a ação que resolveu o problema.
A origem do wait event
Um ponto muito importante para qualquer análise de performance é entender o que acontece “por trás dos panos” no banco de dados. É fundamental que os processos internos sejam conhecidos para que possamos entender a causa dos wait events. Aqui vamos entender o fluxo do redo, que está associado com o Log File Sync.
Os dados de redo são, basicamente, um conjunto de dados que descrevem uma mudança no banco de dados. Qualquer operação que realize uma alteração de um bloco de dados do banco de dados irá gerar dados de redo. Por exemplo, a inserção de dados de tabelas modifica blocos de dados do banco, inserindo novos dados no mesmo, e consequentemente gerando dados de redo, que descrevem essa alteração.
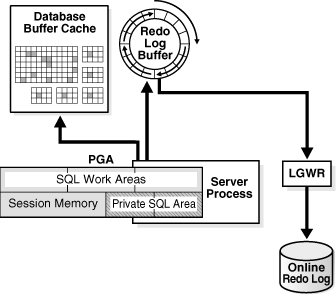
A imagem acima representa as estruturas envolvidas no fluxo do redo. Quando a sessão do usuário estabelece a conexão com o banco Oracle, um server process é criado, para realizar no banco de dados as ações enviadas pelo usuário. No caso da inserção citada anteriormente, ela irá alterar o bloco de dados, presente no Database Buffer Cache, e irá gerar os dados de redo, que serão enviados para uma estrutura em memória, chamada Redo Log Buffer.
Os dados contidos nessa estrutura de memória são periodicamente escritos para disco, através do processo Log Writer (LGWR). Em disco, temos os Online Redo Logs, que são os arquivos para os quais o Log Writer escreve os dados. Essa escrita ocorre de maneira circular:
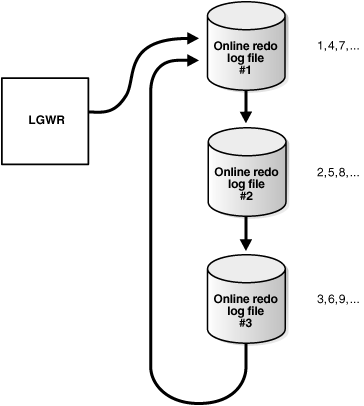
Toda vez que um dos arquivos fica cheio, o LGWR realiza um log switch, passando a escrever no próximo Online Redo Log disponível. Chegando ao último arquivo, o LGWR passa a escrever no arquivo com dados de redo mais antigo.
A escrita para o disco ocorre toda vez que uma das seguintes condições acontece:
- Um usuário commita uma transação;
- Um log switch ocorre;
- Três segundos se passaram desde a última escrita do LGWR;
- O redo log buffer está um terço cheio ou contém 1MB de dados;
- O DBW precisa escrever os dados do database buffer cache em disco.
Quando uma sessão envia um commit para o banco de dados, ela só receberá o retorno de que a sua transação foi de fato commitada após os dados de redo relacionados com a sua transação tenham sido escritos em disco pelo processo LGWR. O wait event Log File Sync representa o intervalo de tempo entre o momento em que o usuário realiza o commit e o retorno da confirmação desse commit para a sessão. Um valor alto para este wait event representa que algo dentro deste processo está demorando demais.
Possíveis causas e soluções
Aqui vão alguns cenários que podem ocasionar o Log File Sync e suas correções:
Lógica de commits da aplicação: caso a aplicação realize commits muito frequentemente podemos ter a incidência de muitos eventos do Log File Sync ocorrendo, com um tempo de espera baixo para cada incidência do evento, mas que no agregado gera um impacto significativo. Nesse cenário uma das possíveis soluções é que seja alterada a lógica da aplicação. Por exemplo: se a aplicação realiza um commit a cada 5 inserções, e é percebido o aumento de Log File Sync, alterar a lógica, fazendo com que a aplicação realize um commit a cada 100 alterações, pode reduzir significativamente o problema. Este cenário entretanto, não foi o verificado no ambiente que estava sendo analisado, pois o Log File Sync aparecia em intervalos de tempos regulares no banco, gerando um tempo de espera grande por incidência, o que indicava uma lógica de commit periódica.
Problemas de I/O: a atividade de escrita e leitura nos discos (I/O) que armazenam os Online Redo Logs pode influenciar no tempo de escrita dos dados de redo para estes arquivos, e consequentemente colaborar com o aumento do Log File Sync. Caso seja verificado esse cenário de uso intensivo dos discos, algumas ações podem ser tomadas, como a movimentação dos Online Redo Logs para discos mais rápidos ou para discos dedicados apenas para estes arquivos, ou a diminuição de uso destes discos. Entretanto, as análises feitas no ambiente demonstraram que os discos estavam abaixo da sua capacidade máxima de IOPS e sua latência de escrita e leitura estavam baixas, o que descartou essa possibilidade.
Uso intensivo de CPU: caso a CPU esteja próxima do limite de utilização, isso pode gerar um impacto negativo para o processo LGWR, que utiliza desse recurso durante a sua operação no fluxo do redo do banco de dados. Caso o cenário seja verificado, deve-se identificar os principais ofensores de CPU para o ambiente, e reduzir seu consumo, ou escalar o hardware em questão. Durante a análise, o uso de CPU estava em torno de 70%, o que também descartou essa hipótese.
Online Redo Logs subdimensionados: em ambientes onde os Online Redo Logs são muito pequenos, os log switches são muito frequentes, o que pode ocasionar um atraso na escrita dos dados de redo para os arquivos, aumentando assim o tempo de wait de Log File Sync. Geralmente neste cenário podemos identificar outros wait events acontecendo no banco, como o Log File Switch Completion e o Log File Switch (Checkpoint Incomplete). Uma boa métrica é analisar a quantidade de log switches por hora no banco. Em um cenário ideal um log switch ocorre a cada 15 a 20 minutos, totalizando de 4 a 5 log switches por hora. Caso o número de log switches por hora seja acima disso, os Online Redo Logs estão subdimensionados e precisam ser alterados. No banco de dados analisado, o número de log switches era de 2 por hora, sendo que alcançava 5 log switches em momentos de pico, o que representa que os Online Redo Logs para a base analisada estão com o tamanho ideal.
Transporte de redo síncrono em configurações Data Guard: em ambientes que fazem parte de uma configuração Data Guard, realizando o envio de redo para um standby em modo síncrono, o tempo do Log File Sync tende a aumentar, devido à natureza do modo de transporte de redo.
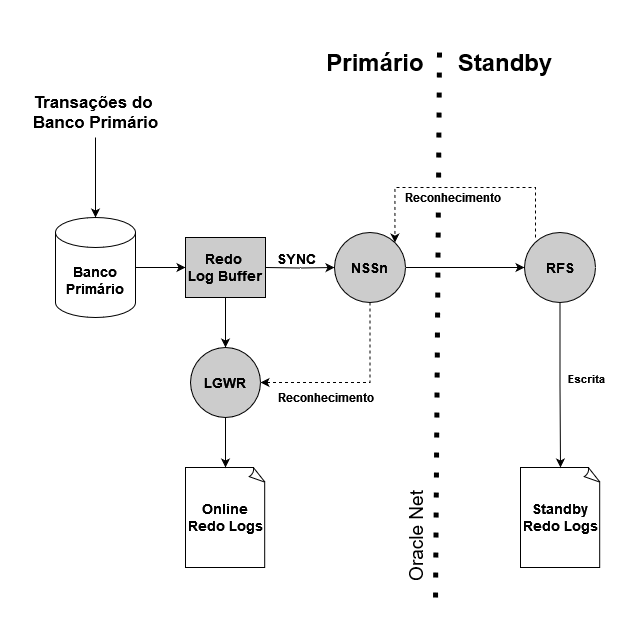
Quando um envio síncrono de redo é utilizado, após o commit da transação, o LGWR só irá confirmar a transação para o usuário após os dados de redo serem escritos nos Online Redo Logs e após o sinal de reconhecimento (ACK) ser enviado do standby e ser recebido pelo LGWR. Esse reconhecimento é enviado em ocasiões diferentes pelo standby, dependendo da configuração do modo de transporte de redo:
- SYNC/NOAFFIRM (FastSync): o sinal de reconhecimento é enviado pelo standby uma vez que o processo RFS receba os dados de redo. Neste modo, o tempo do Log File Sync pode ser impactado pela largura de banda disponível e latência entre o banco primário e o standby;
- SYNC/AFFIRM (Sync): o sinal de reconhecimento é enviado pelo standby uma vez que o processo RFS receba os dados de redo e os escreva nos Standby Redo Logs. Somente quando os dados de redo estão escritos nos Standby Redo Logs é que o sinal de reconhecimento é enviado para o banco primário. Neste modo, o tempo do Log File Sync pode ser impactado pela largura de banda disponível e latência entre o banco primário e o standby, e também pelo tempo de escrita dos dados em disco, nos Standby Redo Logs;
Nesse cenário, também podemos observar outros wait events ocorrendo no banco primário, como Redo Writer Remote Sync Notify e Redo Transport MISC. Para a resolução deste problema pode-se fazer o aumento da banda de rede entre o banco primário e o standby, caso o problema seja uma banda de rede baixa, ou alocar os Standby Redo Logs do standby em discos mais rápidos caso seja verificada uma operação de escrita muito lenta. Em cenários de alta latência entre o primário e o standby, e caso uma licença Active Data Guard tenha sido adquirida, pode-se usar uma instância Far Sync para receber os dados de redo de maneira síncrona e retransmiti-los de maneira assíncrona para o standby. Caso o modo de proteção da configuração Data Guard seja Maximum Performance, ela não necessita de transporte síncrono, e o mesmo pode ser configurado para o modo assíncrono, que não envia o sinal de reconhecimento para o primário, e é o modo de transporte mínimo necessário para este modo de proteção.
Conclusão
No ambiente analisado foram identificados os waits referentes ao modo de transporte de redo síncrono para o standby. Através do Data Guard broker constatou-se que o modo de proteção estava configurado para Maximum Performance, porém o transporte de redo estava configurado para o transporte síncrono. Após ajustado o modo de transporte para o modo assíncrono o Log File Sync deixou de ser o principal wait event do banco e o tempo de resposta do banco de dados para a aplicação passou a ser de três vezes menor.
De modo geral, é fundamental conhecer os procedimentos internos do banco de dados e sua arquitetura para que possamos ser mais rápidos e assertivos durante nossas análises de performance.
Espero que este artigo tenha te ajudado a entender melhor como o Log File Sync acontece.
Grande abraço a todos!
Publicar comentário