
Adaptive Cursor Sharing: Ilustrado na prática
Fala pessoal! No post de hoje iremos falar sobre o Adaptive Cursor Sharing, uma feature do Oracle que nos permite executar diversos planos de execução para o mesmo comando SQL que utiliza de bind variables. Porém, antes de entrar no assunto, vamos rever a base, revisando alguns conceitos importantes.
O que é um cursor?
Quando executamos código SQL ou PL/SQL no banco de dados, os dados referentes às bind variables, estados da sessão e informações sobre o estado de execução da query ficam armazenados na Private SQL Area, que fica dentro da PGA.
O termo cursor remete a um identificador que remete a uma Private SQL Area específica.
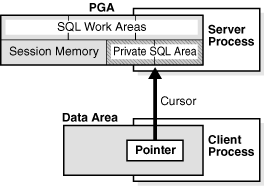
Fonte: Oracle
Então, do lado do client, o cursor pode ser visto como um ponteiro para a Private SQL Area, e no lado do servidor, como um identificador para a mesma .
Esse cursor da Private SQL Area tem uma associação com a Shared SQL Area, que armazena informações como a parse tree (a estrutura hierárquica) e o plano de execução do comando executado.
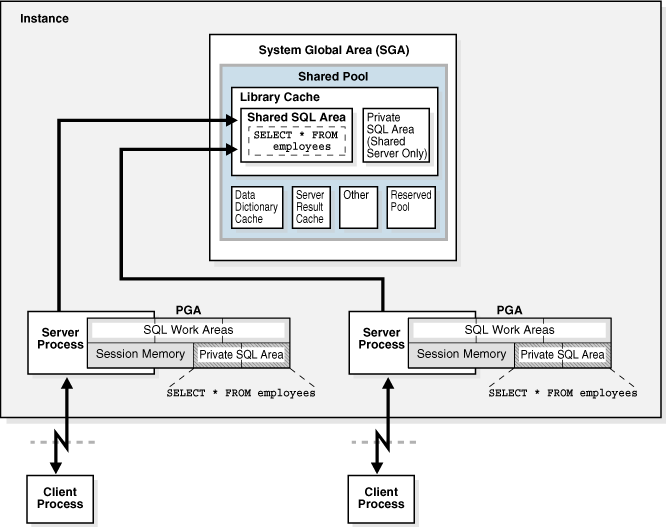
Fonte: Oracle
Diversas Private SQL Areas podem apontar para o mesmo registro da Shared SQL Area, fazendo com que diversas sessões possam utilizar a mesma parse tree e o mesmo plano de execução. Esse compartilhamento do mesmo registro da Shared SQL Area é o que chamamos de Cursor Sharing.
Tal pai, tal filho, mas nem sempre
Todo SQL tem um cursor pai (parent cursor) e um ou mais cursores filho (child cursor). No parent cursor é onde fica armazenado o texto do SQL, e caso dois SQLs tenham o mesmo texto, eles irão compartilhar o mesmo parent cursor.
Já nos child cursors é onde ficam o plano de execução, bind variables e metadados sobre os objetos referenciados pela query. Caso o comando SQL compartilhe o parent cursor com outro SQL, o Oracle verifica se eles também podem compartilhar o mesmo child cursor, através de análises dos metadados de objetos referenciados, modo de otimizador, e outros.
Por exemplo, vejamos o seguinte cenário:
SQL> conn hr@pdb
Enter password:
SQL> select count(*) from employees;
COUNT(*)
----------
107
SQL> select count(*) from Employees;
COUNT(*)
----------
107
SQL> conn tiago@pdb
Enter password:
Connected.
SQL> select count(*) from employees;
COUNT(*)
----------
107
Inicialmente duas queries são executadas com o usuário HR, buscando dados da tabela “employees”, e depois, uma query é executada com o usuário TIAGO, também buscando dados da tabela “employees”. O que acontece aqui é que duas tabelas “employees” diferentes estão sendo buscadas, uma no schema HR e outra no schema TIAGO. Vamos analisar os cursores:
SQL> SELECT SQL_ID, PARSING_SCHEMA_NAME AS SCHEMA, SQL_TEXT, CHILD_NUMBER AS CHILD#, EXECUTIONS AS EXEC FROM V$SQL WHERE SQL_TEXT LIKE '%mployees%' AND SQL_TEXT NOT LIKE '%SQL_TEXT%' ORDER BY SQL_ID; SQL_ID SCHEM SQL_TEXT CHILD# EXEC ------------- ----- ---------------------------------------------------------------------- ---------- ---------- 6wa8haryg7crv HR select count(*) from Employees 0 1 7c1rnh08dp922 HR select count(*) from employees 0 1 7c1rnh08dp922 TIAGO select count(*) from employees 1 1
No caso das queries executadas pelo usuário HR, cada uma tem um parent cursor diferente (coluna CHILD# igual a 0) pois são os SQLs são sintaticamente diferentes, ou seja, tem seu SQL Text diferente. Já o SQL executado pelo usuário TIAGO tem seu parent cursor compartilhado com a query do usuário HR, porém um novo child cursor foi criado, devido à diferença semântica entre as queries, devido ao fato de fazerem referência a diferentes objetos.
A importância do uso de bind variables
Para determinar se é possível realizar o Cursor Sharing, o Oracle utiliza de um valor de hash para o comando SQL, com base no texto da sua query. Quando uma sessão executa um SQL, uma busca pelo hash é feita na Shared SQL Area. Caso o hash não exista, um hard parse precisará ser feito. Entretanto, caso o hash exista, uma análise do texto da query é feita, para verificar se o registro contido em memória é idêntico (caractere a caractere) ao que está sendo executado. Caso o hash seja idêntico, mas o texto seja diferente (cenário de colisão de hash) o hard parse é feito.
Por exemplo, analisando as queries abaixo, executadas pelo usuário HR:
SQL> select department_name from departments where department_id = 10; DEPARTMENT_NAME ------------------------------ Administration SQL> select department_name from departments where department_id = 20; DEPARTMENT_NAME ------------------------------ Marketing SQL> select department_name from departments where department_id = 30; DEPARTMENT_NAME ------------------------------ Purchasing SQL> select department_name from Departments where department_id = 30; DEPARTMENT_NAME ------------------------------ Purchasing
Olhando os dados da view V$SQLAREA, podemos ver que todos as quatro queries possuem hash values diferentes, inclusive as últimas duas executadas, onde apenas a letra “D” da tabela “departments” foi alterada para maiúscula:
SQL> SELECT SQL_TEXT, SQL_ID, VERSION_COUNT, HASH_VALUE FROM V$SQLAREA WHERE SQL_TEXT LIKE '%department%' AND SQL_TEXT NOT LIKE '%SQL_TEXT%'; SQL_TEXT SQL_ID VERSION_COUNT HASH_VALUE ---------------------------------------------------------------------- ------------- ------------- ---------- select department_name from departments where department_id = 10 c3jp9mt6ph788 1 1297620232 select department_name from departments where department_id = 30 gy40cvphyw8t3 1 1642996515 select department_name from departments where department_id = 20 caa430xcs9djm 1 1501869619 select department_name from Departments where department_id = 30 9jc8jw7p53gcr 1 3931225495
Nesse cenário, cada execução está realizando um hard parse, sem a reutilização de cursores.
Para todos os exemplos acima, estamos usando o que chamamos de literais, onde colocamos o valor de uma forma “hard coded” na query. Essa não é uma boa prática justamente pelo fato de que cada query terá seu SQL Text e conquentemente um hash value diferente, e um parent cursor precisará ser aberto para cada execução com valores diferentes na cláusula WHERE.
Para solucionar o problema, devemos usar bind variables:
SQL> variable dept_id number; SQL> exec :dept_id := 10; PL/SQL procedure successfully completed. SQL> select department_name from departments where department_id = :dept_id; DEPARTMENT_NAME ------------------------------ Administration SQL> exec :dept_id := 20; PL/SQL procedure successfully completed. SQL> select department_name from departments where department_id = :dept_id; DEPARTMENT_NAME ------------------------------ Marketing SQL> exec :dept_id := 30; PL/SQL procedure successfully completed. SQL> select department_name from departments where department_id = :dept_id; DEPARTMENT_NAME ------------------------------ Purchasing
Analisando os cursores:
SELECT SQL_TEXT, SQL_ID, VERSION_COUNT, HASH_VALUE FROM V$SQLAREA WHERE SQL_TEXT LIKE '%= :dept%' AND SQL_TEXT NOT LIKE '%SQL_TEXT%'; SQL_TEXT SQL_ID VERSION_COUNT HASH_VALUE ---------------------------------------------------------------------- ------------- ------------- ---------- select department_name from departments where department_id = :dept_id 4j8u3q4bxwf72 1 400439522
Para este exemplo, conseguimos reutilizar o mesmo cursor para três execuções da query, mesmo usando diferentes valores para a bind variable. O banco agradece!
O Adaptive Cursor Sharing
O exemplo anterior mostra que o mesmo cursor, e consequentemente o mesmo plano, foi utilizado para as três consultas, mas nem sempre esse é o cenário ideal. Por exemplo, quando determinado valor sendo filtrado no predicado da consulta (na sua cláusula WHERE) tem uma alta seletividade, como quando determinado valor ultrapassa 50% do total de registros da tabela, o plano pode optar por executar um FULL TABLE SCAN, enquanto com uma baixa seletividade, digamos de 5% dos registros da tabela, o plano pode solicitar um INDEX RANGE SCAN. E é aí que o Adaptive Cursor Sharing entra em ação.
Pra entender a dinâmica do Adaptive Cursor Sharing funciona, vamos criar duas tabelas dentro do schema TIAGO, e inserir 1 milhão de registros em cada, criar dois índices na coluna que vamos utilizar para filtrar as queries e realizar a coleta de estatísticas, gerando um histograma nas colunas, para que melhores estimativas sejam geradas:
conn tiago@pdb
CREATE TABLE T1 (
T1_ID NUMBER PRIMARY KEY,
T1_DESC VARCHAR2(10)
);
CREATE TABLE T2 (
T2_ID NUMBER PRIMARY KEY,
T2_DESC VARCHAR2(10),
T1_ID NUMBER,
FOREIGN KEY (T1_ID) REFERENCES T1(T1_ID)
);
BEGIN
FOR i IN 1..1000000 LOOP
IF i <= 600000 THEN
INSERT INTO T1 VALUES (i, 'A');
ELSIF i > 600000 AND i <= 800000 THEN
INSERT INTO T1 VALUES (i, 'B');
ELSIF i > 800000 AND i <= 900000 THEN
INSERT INTO T1 VALUES (i, 'C');
ELSE INSERT INTO T1 VALUES (i, 'D');
END IF;
END LOOP;
COMMIT;
END;
/
DECLARE
letra VARCHAR2(1);
BEGIN
FOR i IN 1..1000000 LOOP
letra := CASE MOD(i, 20)
WHEN 0 THEN 'A'
WHEN 1 THEN 'A'
WHEN 2 THEN 'A'
WHEN 3 THEN 'A'
WHEN 4 THEN 'A'
WHEN 5 THEN 'A'
WHEN 6 THEN 'A'
WHEN 7 THEN 'A'
WHEN 8 THEN 'A'
WHEN 9 THEN 'A'
WHEN 10 THEN 'A'
WHEN 11 THEN 'B'
WHEN 12 THEN 'B'
WHEN 13 THEN 'B'
WHEN 14 THEN 'B'
WHEN 15 THEN 'C'
WHEN 16 THEN 'C'
WHEN 17 THEN 'C'
WHEN 18 THEN 'D'
WHEN 19 THEN 'D'
END;
INSERT INTO T2 VALUES (i, letra, i);
END LOOP;
COMMIT;
END;
/
CREATE INDEX IDX_01 ON T1(T1_DESC);
CREATE INDEX IDX_02 ON T2(T2_DESC);
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(
ownname => 'TIAGO',
tabname => 'T1',
method_opt => 'FOR ALL COLUMNS SIZE SKEWONLY',
cascade => TRUE,
estimate_percent => dbms_stats.auto_sample_size
);
END;
/
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(
ownname => 'TIAGO',
tabname => 'T2',
method_opt => 'FOR ALL COLUMNS SIZE SKEWONLY',
cascade => TRUE,
estimate_percent => dbms_stats.auto_sample_size
);
END;
/
A seletividade das colunas que serão usadas para filtragem são mostradas abaixo:
SQL> SELECT T1_DESC, COUNT(1) Count, COUNT(1)/1000000 Selectivity FROM T1 GROUP BY T1_DESC ORDER BY 2 DESC; T1_DESC COUNT SELECTIVITY -------------------------------------------------- ---------- ----------- A 600000 .6 B 200000 .2 D 100000 .1 C 100000 .1 SQL> SELECT T2_DESC, COUNT(1) Count, COUNT(1)/1000000 Selectivity FROM T2 GROUP BY T2_DESC ORDER BY 2 DESC; T2_DESC COUNT SELECTIVITY -------------------------------------------------- ---------- ----------- A 550000 .55 B 200000 .2 C 150000 .15 D 100000 .1
Vamos começar com uma consulta, testando os valores com maior seletividade calculada:
SQL> VARIABLE desc1 VARCHAR2(1);
SQL> VARIABLE desc2 VARCHAR2(1);
SQL> EXEC :desc1 := 'A'
PL/SQL procedure successfully completed.
SQL> EXEC :desc2 := 'A'
PL/SQL procedure successfully completed.
SQL> SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID
WHERE T1_DESC = :desc1 AND T2_DESC = :desc2; 2
COUNT(*)
----------
330000
SQL> SET LINES WINDOW
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR);SQL>
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID d39fqfawqv2k1, child number 0
-------------------------------------
SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID WHERE T1_DESC =
:desc1 AND T2_DESC = :desc2
Plan hash value: 4274056747
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 2181 (100)| |
| 1 | SORT AGGREGATE | | 1 | 14 | | | |
|* 2 | HASH JOIN | | 550K| 7519K| 9M| 2181 (2)| 00:00:01 |
|* 3 | TABLE ACCESS FULL| T2 | 550K| 3759K| | 656 (2)| 00:00:01 |
|* 4 | TABLE ACCESS FULL| T1 | 600K| 4101K| | 485 (2)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."T1_ID"="T2"."T1_ID")
3 - filter("T2"."T2_DESC"=:DESC2)
4 - filter("T1"."T1_DESC"=:DESC1)
Note
-----
- this is an adaptive plan
28 rows selected.
Como esperado, devido à seletividade de ambos os valores usados nas bind variables ultrapassarem 50%, o plano de execução realiza o TABLE ACCESS FULL para buscar os dados. Analisando alguns dados do cursor, temos a criação do parent cursor:
SQL> col BIND_SENS for a10
SQL> col BIND_AWARE for a10
SQL> col SHARABLE for a10
SQL> SELECT SQL_ID, CHILD_NUMBER AS CHILD#, PLAN_HASH_VALUE, EXECUTIONS AS EXEC,
BUFFER_GETS AS BUFF_GETS, IS_BIND_SENSITIVE AS BIND_SENS,
IS_BIND_AWARE AS BIND_AWARE, IS_SHAREABLE AS SHAREABLE
FROM V$SQL
WHERE SQL_ID = 'd39fqfawqv2k1';
SQL_ID CHILD# PLAN_HASH_VALUE EXEC BUFF_GETS BIND_SENS BIND_AWARE SHAREABLE
------------- ---------- --------------- ---------- ---------- ---------- ---------- ----------
d39fqfawqv2k1 0 4274056747 1 4104 Y N Y
Para essa execução, o Oracle realizou um hard parse, e determinou o plano de execução de acordo com o valor da bind variable (essa verificação do valor da bind se chama bind peeking). Como estamos usando bind variables, o cursor é marcado como bind sensitive, o que pode ser visto na consulta acima, na coluna BIND_SENS. Isso indica que a escolha do plano de execução com melhor performance pode depender do valor dessa variável. A coluna SHAREABLE indica que o cursor pode ser compartilhável.
Agora vamos para outro teste, porém usando valores com menores seletividades para as bind variables:
SQL> EXEC :desc1 := 'D'
PL/SQL procedure successfully completed.
SQL> EXEC :desc2 := 'D'
PL/SQL procedure successfully completed.
SQL> SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID
WHERE T1_DESC = :desc1 AND T2_DESC = :desc2; 2
COUNT(*)
----------
10000
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID d39fqfawqv2k1, child number 0
-------------------------------------
SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID WHERE T1_DESC =
:desc1 AND T2_DESC = :desc2
Plan hash value: 4274056747
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 2181 (100)| |
| 1 | SORT AGGREGATE | | 1 | 14 | | | |
|* 2 | HASH JOIN | | 550K| 7519K| 9M| 2181 (2)| 00:00:01 |
|* 3 | TABLE ACCESS FULL| T2 | 550K| 3759K| | 656 (2)| 00:00:01 |
|* 4 | TABLE ACCESS FULL| T1 | 600K| 4101K| | 485 (2)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."T1_ID"="T2"."T1_ID")
3 - filter("T2"."T2_DESC"=:DESC2)
4 - filter("T1"."T1_DESC"=:DESC1)
Note
-----
- this is an adaptive plan
28 rows selected.
Durante essa segunda execução, o Oracle ainda usa o mesmo plano de execução, mesmo ele não sendo o melhor que podemos ter. Sabemos disso, porque temos índices para as colunas T1_DESC e T2_DESC, e devido à baixa seletividade, eles seriam benéficos.
Também podemos ver que o banco reutilizou o cursor através da consulta:
SQL> SELECT SQL_ID, CHILD_NUMBER AS CHILD#, PLAN_HASH_VALUE, EXECUTIONS AS EXEC,
BUFFER_GETS AS BUFF_GETS, IS_BIND_SENSITIVE AS BIND_SENS,
IS_BIND_AWARE AS BIND_AWARE, IS_SHAREABLE AS SHAREABLE
FROM V$SQL
WHERE SQL_ID = 'd39fqfawqv2k1';
SQL_ID CHILD# PLAN_HASH_VALUE EXEC BUFF_GETS BIND_SENS BIND_AWARE S
------------- ---------- --------------- ---------- ---------- ---------- ---------- -
d39fqfawqv2k1 0 4274056747 2 8198 Y N Y
Então por que o Oracle não usou os índices aqui?
Após essa segunda execução, o Oracle compara as estatísticas de execução da segunda execução com as estatísticas da primeira e decide se vai tornar o cursor bind aware. Um cursor bind aware significa que o cursor pode usar diferentes planos de execução de acordo com o valor das bind variables passadas na query.
Vamos executar novamente a query, mantendo os valores das bind variables, e ver o que acontece agora:
SQL> SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID
WHERE T1_DESC = :desc1 AND T2_DESC = :desc2; 2
COUNT(*)
----------
10000
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID d39fqfawqv2k1, child number 1
-------------------------------------
SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID WHERE T1_DESC =
:desc1 AND T2_DESC = :desc2
Plan hash value: 258474461
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 1189 (100)| |
| 1 | SORT AGGREGATE | | 1 | 14 | | | |
|* 2 | HASH JOIN | | 99999 | 1367K| 1856K| 1189 (1)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 100K| 683K| | 351 (1)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IDX_01 | 100K| | | 185 (1)| 00:00:01 |
|* 5 | TABLE ACCESS FULL | T2 | 100K| 683K| | 656 (2)| 00:00:01 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."T1_ID"="T2"."T1_ID")
4 - access("T1"."T1_DESC"=:DESC1)
5 - filter("T2"."T2_DESC"=:DESC2)
25 rows selected.
Agora, nessa nova execução, o plano de execução foi alterado, passando a utilizar um índice para acesso na tabela T1.
Neste ponto, vamos começar a olhar para a seletividade dos valores envolvidos. Para isso, vou utilizar gráficos, pra tornar a compreensão um pouco mais fácil. No gráfico abaixo, o eixo X remete à seletividade dos valores da coluna T1_DESC da tabela T1, e o eixo Y remete à seletividade dos valores da coluna T2_DESC da tabela T2:
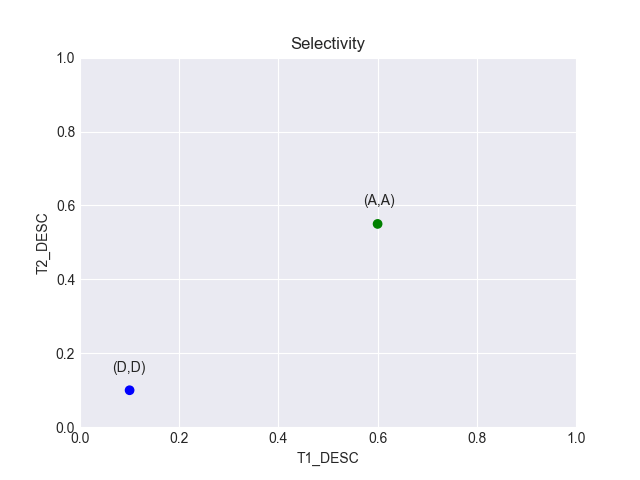
Usando o gráfico, podemos ver de uma maneira mais evidente a diferença entre as seletividades, e será fundamental pra demonstrar como o Adaptive Cursor Sharing funciona mais à frente.
Vamos ao comportamento dos cursores:
SQL> SELECT SQL_ID, CHILD_NUMBER AS CHILD#, PLAN_HASH_VALUE, EXECUTIONS AS EXEC,
BUFFER_GETS AS BUFF_GETS, IS_BIND_SENSITIVE AS BIND_SENS,
IS_BIND_AWARE AS BIND_AWARE, IS_SHAREABLE AS SHAREABLE
FROM V$SQL
WHERE SQL_ID = 'd39fqfawqv2k1';
SQL_ID CHILD# PLAN_HASH_VALUE EXEC BUFF_GETS BIND_SENS BIND_AWARE S
------------- ---------- --------------- ---------- ---------- ---------- ---------- -
d39fqfawqv2k1 0 4274056747 2 8198 Y N N
d39fqfawqv2k1 1 258474461 1 2741 Y Y Y
Agora um novo child cursor foi criado, com o plan hash value do plano de execução ótimo para esta query, e o cursor foi marcado como bind aware, uma vez que o valor das bind variables pode afetar na escolha do plano de execução ótimo.
Outro ponto importante aqui é que o Oracle marca o child cursor de número 0 (zero) como “non shareable”, ou seja, ele foi invalidado, não será mais utilizado e com o tempo será removido da Shared Pool.
Agora que temos um cursor bind aware, o Oracle começa a trabalhar com o Selectivity Cube, que são intervalos de valores de selectividade para o qual o cursor é válido. Podemos verificar esses valores através da view V$SQL_CS_SELECTIVITY:
SQL> select child_number, range_id, predicate, low, high from v$sql_cs_selectivity where sql_id ='d39fqfawqv2k1';
CHILD_NUMBER RANGE_ID PREDICATE LOW HIGH
------------ ---------- ---------------------------------------- ---------- ----------
1 0 =DESC1 0.090000 0.109999
1 0 =DESC2 0.090000 0.109999
Esse intervalo de valores é calculado como um offset de 10% da seletividade real dos valores passados na bind variable. Para este child cursor número 1, por exemplo, temos a seletividade de 0.1 para ambas as binds, o que significa que temos:
- 0.1 – 10% = 0.9 => valor da coluna LOW da view acima;
- 0.1 + 10% = 1.1 => valor da coluna HIGH da view acima (arredondado);
Podemos representar esses valores de LOW e HIGH de ambas as variáveis no nosso gráfico, dando visibilidade ao Selectivity Cube. Dessa vez vamos usar uma escala logarítmica no gráfico para melhor visualização:
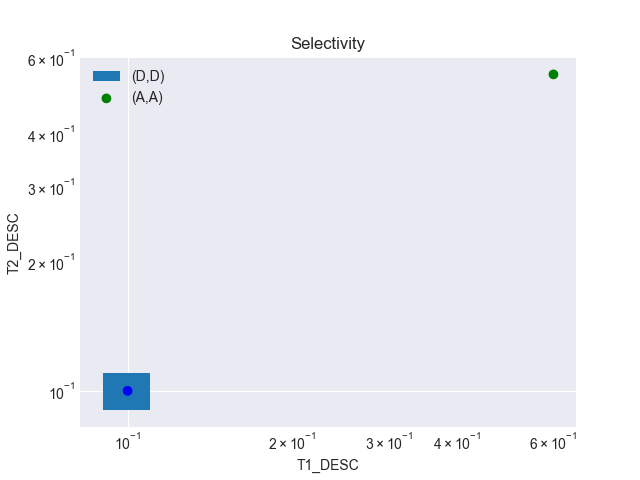
Nesse cenário, caso ocorra a execução de uma nova query com diferentes valores de bind variables, mas que a sua seletividade se encaixe dentro do selectivity cube existente, não existe a necessidade para um novo hard parse.
Mas e agora, o que acontece se tentarmos executar a consulta novamente com os valores com maior seletividade calculada nas bind variables? Vamos ao teste:
SQL> EXEC :desc1 := 'A'
PL/SQL procedure successfully completed.
SQL> EXEC :desc2 := 'A'
PL/SQL procedure successfully completed.
SQL> SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID
WHERE T1_DESC = :desc1 AND T2_DESC = :desc2; 2
COUNT(*)
----------
330000
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID d39fqfawqv2k1, child number 2
-------------------------------------
SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID WHERE T1_DESC =
:desc1 AND T2_DESC = :desc2
Plan hash value: 4274056747
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 2181 (100)| |
| 1 | SORT AGGREGATE | | 1 | 14 | | | |
|* 2 | HASH JOIN | | 550K| 7519K| 9M| 2181 (2)| 00:00:01 |
|* 3 | TABLE ACCESS FULL| T2 | 550K| 3759K| | 656 (2)| 00:00:01 |
|* 4 | TABLE ACCESS FULL| T1 | 600K| 4101K| | 485 (2)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."T1_ID"="T2"."T1_ID")
3 - filter("T2"."T2_DESC"=:DESC2)
4 - filter("T1"."T1_DESC"=:DESC1)
Note
-----
- this is an adaptive plan
28 rows selected.
De acordo com o plano de execução, voltamos a ter os dois TABLE ACCESS FULL acontecendo. Na própria saída do DBMS_XPLAN.DISPLAY_CURSOR podemos notar a existência de um novo child cursor. Isso aconteceu porque o Oracle invalidou o child cursor que continha o mesmo plano de execução. Vamos olhar suas propriedades:
SQL> SELECT SQL_ID, CHILD_NUMBER AS CHILD#, PLAN_HASH_VALUE, EXECUTIONS AS EXEC,
BUFFER_GETS AS BUFF_GETS, IS_BIND_SENSITIVE AS BIND_SENS,
IS_BIND_AWARE AS BIND_AWARE, IS_SHAREABLE AS SHAREABLE
FROM V$SQL
WHERE SQL_ID = 'd39fqfawqv2k1';
SQL_ID CHILD# PLAN_HASH_VALUE EXEC BUFF_GETS BIND_SENS BIND_AWARE S
------------- ---------- --------------- ---------- ---------- ---------- ---------- -
d39fqfawqv2k1 0 4274056747 2 8198 Y N N
d39fqfawqv2k1 1 258474461 1 2741 Y Y Y
d39fqfawqv2k1 2 4274056747 1 4094 Y Y Y
Agora temos dois cursores compartilháveis sendo utilizados, cada um tendo um plano de execução diferente para o mesmo SQL.
Vamos à consulta do Selectivity Cube:
SQL> select child_number, range_id, predicate, low, high from v$sql_cs_selectivity where sql_id ='d39fqfawqv2k1';
CHILD_NUMBER RANGE_ID PREDICATE LOW HIGH
------------ ---------- ---------------------------------------- ---------- ----------
2 0 =DESC1 0.540000 0.660000
2 0 =DESC2 0.495000 0.605000
1 0 =DESC1 0.090000 0.109999
1 0 =DESC2 0.090000 0.109999
Neste momento temos um novo range de valores, agora para o child cursor de número 2. Atualizando nosso gráfico de seletividade, temos o segundo selectivity cube plotado:
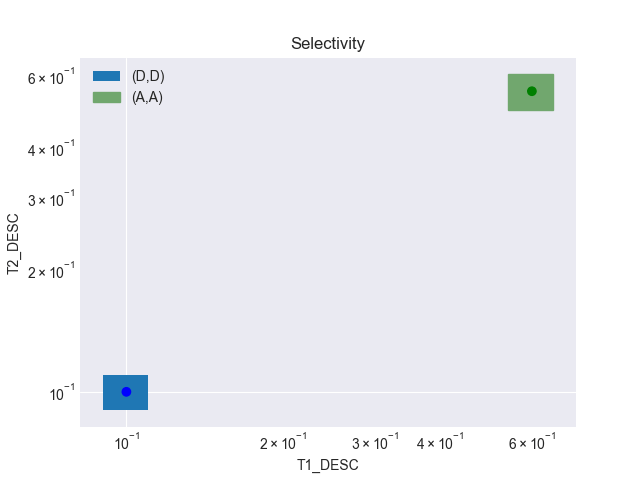
A união faz a força
Agora que temos dois selectivity cubes distintos, vamos tentar realizar uma nova consulta com valores de bind variables diferentes, mantendo uma baixa seletividade:
SQL> EXEC :desc1 := 'D'
PL/SQL procedure successfully completed.
SQL> EXEC :desc2 := 'C'
PL/SQL procedure successfully completed.
SQL> SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID
WHERE T1_DESC = :desc1 AND T2_DESC = :desc2; 2
COUNT(*)
----------
15000
SQL> SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR);
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID d39fqfawqv2k1, child number 3
-------------------------------------
SELECT COUNT(*) FROM T1 JOIN T2 ON T1.T1_ID = T2.T1_ID WHERE T1_DESC =
:desc1 AND T2_DESC = :desc2
Plan hash value: 258474461
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | | 1234 (100)| |
| 1 | SORT AGGREGATE | | 1 | 14 | | | |
|* 2 | HASH JOIN | | 100K| 1367K| 1856K| 1234 (1)| 00:00:01 |
| 3 | TABLE ACCESS BY INDEX ROWID BATCHED| T1 | 100K| 683K| | 351 (1)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IDX_01 | 100K| | | 185 (1)| 00:00:01 |
|* 5 | TABLE ACCESS FULL | T2 | 150K| 1025K| | 656 (2)| 00:00:01 |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T1"."T1_ID"="T2"."T1_ID")
4 - access("T1"."T1_DESC"=:DESC1)
5 - filter("T2"."T2_DESC"=:DESC2)
25 rows selected.
Antes de analisarmos os cursores, vamos calcular os valores do selectivity cube, e posteriormente tirar a prova real através das views:
| COLUNA | SELETIVIDADE | LOW (SEL. – 10%) | HIGH (SEL. +10%) |
| T1_DESC = ‘D’ | 0.1 | 0.9 | 1.1 |
| T2_DESC = ‘C’ | 0.15 | 0.135 | 0.165 |
Analisando os cursores:
SQL> SELECT SQL_ID, CHILD_NUMBER AS CHILD#, PLAN_HASH_VALUE, EXECUTIONS AS EXEC,
BUFFER_GETS AS BUFF_GETS, IS_BIND_SENSITIVE AS BIND_SENS,
IS_BIND_AWARE AS BIND_AWARE, IS_SHAREABLE AS SHAREABLE
FROM V$SQL
WHERE SQL_ID = 'd39fqfawqv2k1'; 2 3 4 5
SQL_ID CHILD# PLAN_HASH_VALUE EXEC BUFF_GETS BIND_SENS BIND_AWARE S
------------- ---------- --------------- ---------- ---------- ---------- ---------- -
d39fqfawqv2k1 0 4274056747 2 8198 Y N N
d39fqfawqv2k1 1 258474461 1 2741 Y Y N
d39fqfawqv2k1 2 4274056747 1 4094 Y Y Y
d39fqfawqv2k1 3 258474461 1 2763 Y Y Y
Aqui podemos ver que o banco de dados criou um novo child cursor de número 3. Quando analisamos os valores de seletividade, esse comportamento era esperado, pois o cubo resultante dos valores LOW e HIGH da última query não entram no cubo já existente do child cursor 1. Mas temos um dado interessante: tanto o child cursor 1 quanto o 3 usam o mesmo plano de execução.
Além disso, vemos que o Oracle marcou o child cursor 1 como “non shareable”. Vou explicar isso logo mais.
Vamos plotar essas informações no nosso gráfico, adicionando o selectivity cube do child cursor 3:
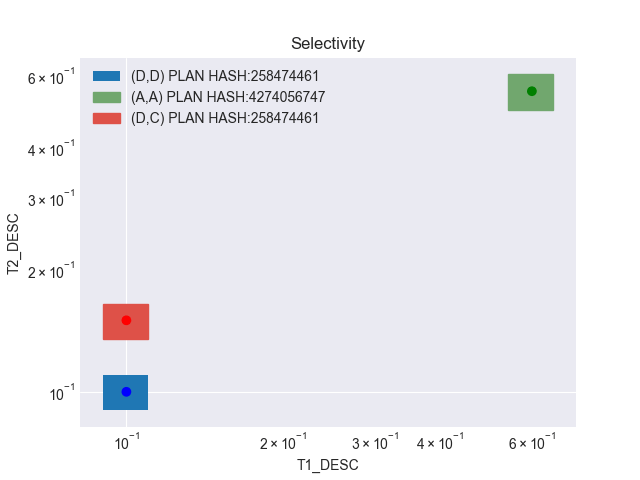
Agora vamos ver os dados da view V$SQL_CS_SELECTIVITY:
SQL> select child_number, range_id, predicate, low, high from v$sql_cs_selectivity where sql_id ='d39fqfawqv2k1';
CHILD_NUMBER RANGE_ID PREDICATE LOW HIGH
------------ ---------- ---------------------------------------- ---------- ----------
3 0 =DESC1 0.090000 0.109999
3 0 =DESC2 0.090000 0.165000
2 0 =DESC1 0.540000 0.660000
2 0 =DESC2 0.495000 0.605000
1 0 =DESC1 0.090000 0.109999
1 0 =DESC2 0.090000 0.109999
Olhando o valor LOW da bind variable DESC2 do child cursor 3, vemos uma divergência em relação aos nossos cálculos. Erramos?
A resposta é: não. O Adaptive Cursor Sharing executou aqui um operação que se chama Cursor Merge. O Oracle identificou que ambos os cursores tem o mesmo plano de execução, e para liberar espaço na Library Cache, ele invalida um dos cursores, e atualiza o selectivity cube do outro cursor para agregar a seletividade que o cursor invalidado continha. No nosso caso, o valor LOW da bind DESC2 do child cursor 3 que deveria ser 0.135 passa a ser 0.9, pois é o valor LOW da bind DESC2 do child cursor 1, que foi invalidado.
Fica mais fácil quando olhamos para o gráfico:

Conclusão
Ufa! Chegamos ao final do artigo e espero que você tenha aprendido algo novo.
Recomendo bastante que você visite o material que inspirou esse artigo: o blog do Mohamed Houri, através do artigo Cursor selectivity cube -Part I e a própria documentação Oracle, Improving Real-World Performance Through Cursor Sharing.
Forte abraço a todos!
2 comments