
Como funciona o Advanced Row Compression?
Fala pessoal! No post de hoje vamos nos aprofundar na compressão de tabelas do Oracle e entender como funciona o Advanced Row Compression.
O que é o Advanced Row Compression?
O Advanced Row Compression é uma funcionalidade, pertencente à option Advanced Compression do Oracle (necessita licenciamento adicional ao EE), que permite a compressão de dados de tabelas. O principal foco dessa funcionalidade é otimizar ambientes OLTP, pois permite que a compressão seja feita em operações como INSERTs e UPDATEs, além das inserções via direct path. Além disso, a compressão é feita de uma forma totalmente transparente para a aplicação, sem necessidade de configurações adicionais na mesma.
Segundo a Oracle, podemos ter um ganho de 50% ou mais de espaço em disco com a utilização dessa feature, o que estaremos calculando mais tarde neste artigo, em um exemplo que veremos.
Como acontece a compressão dos dados?
A compressão dos dados de tabelas no Oracle ocorre através da eliminação de valores duplicados a nível de data block. Os dados são inicialmente inseridos no data block sem compressão alguma, e uma vez que o espaço livre no bloco alcança o valor de PCTFREE (por padrão 10%), a compressão é disparada. Durante a primeira compressão, uma symbol table é criada dentro do data block.
De maneira conceitual, podemos imaginar os seguintes dados inseridos em um data block:

Fonte: Oracle
Após a compressão os dados repetidos são substituídos por “símbolos”:

Fonte: Oracle
A symbol table criada conteria a associação do símbolo inserido no data block com o valor que foi substituído, e a referência da linha:
| Símbolo | Valor | Coluna | Linhas |
| * | 29-NOV-00 | 3 | 958-960 |
| % | 9999 | 5 | 956-960 |
Mais tarde veremos que dentro do data block nem tudo é tão simples assim.
Após a compressão, quando novas inserções ocorrem no data block, os dados inseridos não são comprimidos inicialmente, e uma nova compressão só ocorre quando o espaço livre do bloco alcança o valor de PCTFREE. Nesse caso, podemos ter um cenário onde uma operação de INSERT pode liberar espaço no Oracle (bem contraintuitivo, não?).
Abaixo o esquema que representa esse fluxo:
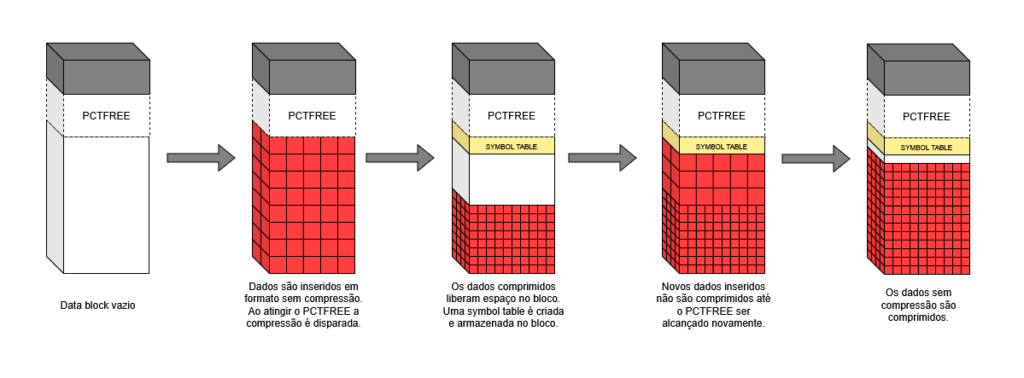
Fonte: autoria própria
Um grande benefício da compressão é que ela remove o espaço livre fragmentado que ocorre normalmente nos data blocks. Outra grande vantagem aqui é a otimização do Database Buffer Cache, uma vez que cada data block armazena mais informações, podemos ter mais dados em cache do que teríamos sem a compressão.
Como funciona o Advanced Row Compression na prática
Para uma visão prática da implementação do Advanced Row Compression, vamos iniciar criando uma tablespace que irá hospedar uma tabela sem compressão. A estrutura base da tabela está sendo copiada da tabela SALES, do schema SH:
SQL> conn sh/sh@pdb Connected. SQL> SQL> CREATE TABLESPACE TBS_NOCOMPRESS; Tablespace created. SQL> CREATE TABLE NOCOMPRESSED TABLESPACE TBS_NOCOMPRESS AS SELECT * FROM SH.SALES WHERE 1=2; Table created. SQL> DESC NOCOMPRESSED Name Null? Type ----------------------------------------- -------- ---------------------------- PROD_ID NOT NULL NUMBER(6) CUST_ID NOT NULL NUMBER TIME_ID NOT NULL DATE CHANNEL_ID NOT NULL NUMBER(1) PROMO_ID NOT NULL NUMBER(6) QUANTITY_SOLD NOT NULL NUMBER(3) AMOUNT_SOLD NOT NULL NUMBER(10,2)
Em seguida, vamos criar uma segunda tablespace, que irá hospedar a tabela com o Advanced Row Compression habilitado:
SQL> CREATE TABLESPACE TBS_COMPRESS; Tablespace created. SQL> CREATE TABLE COMPRESSED TABLESPACE TBS_COMPRESS AS SELECT * FROM SH.SALES WHERE 1=2; Table created. SQL> ALTER TABLE COMPRESSED ROW STORE COMPRESS ADVANCED; --> habilitado o Advanced Row Compress para a tabela "Compressed" Table altered.
Os dados de compressão já podem ser vistos na view DBA_TABLES:
SQL> SET LINES WINDOW
SQL> COL TABLE_NAME FOR A15
SQL> SELECT TABLE_NAME, COMPRESSION, COMPRESS_FOR FROM DBA_TABLES WHERE TABLE_NAME IN ('COMPRESSED', 'NOCOMPRESSED');
TABLE_NAME COMPRESS COMPRESS_FOR
--------------- -------- ------------------------------
NOCOMPRESSED DISABLED
COMPRESSED ENABLED ADVANCED
Agora vamos inserir dados na tabela sem compressão:
SQL> INSERT INTO NOCOMPRESSED SELECT * FROM SH.SALES FETCH FIRST 100000 ROWS ONLY; 100000 rows created. SQL> COMMIT; Commit complete.
Oracle Compression Advisor
Neste ponto, podemos fazer uma análise do possível ganho de espaço que teríamos com a compressão, utilizando o Compression Advisor, através da package DBMS_COMPRESSION (esta package não requer o licenciamento Advanced Compression):
SQL> SET SERVEROUTPUT ON DECLARE l_blkcnt_cmp PLS_INTEGER; l_blkcnt_uncmp PLS_INTEGER; l_row_cmp PLS_INTEGER; l_row_uncmp PLS_INTEGER; l_cmp_ratio NUMBER; l_comptype_str VARCHAR2(32767); BEGIN DBMS_COMPRESSION.GET_COMPRESSION_RATIO ( scratchtbsname => 'TBS_NOCOMPRESS' , ownname => 'TIAGO' , objname => 'NOCOMPRESSED' , subobjname => NULL , comptype => DBMS_COMPRESSION.COMP_ADVANCED, blkcnt_cmp => l_blkcnt_cmp, blkcnt_uncmp => l_blkcnt_uncmp, row_cmp => l_row_cmp, row_uncmp => l_row_uncmp, cmp_ratio => l_cmp_ratio, comptype_str => l_comptype_str ); DBMS_OUTPUT.put_line( 'Number of blocks used by the compressed sample of the object : ' || l_blkcnt_cmp); DBMS_OUTPUT.put_line( 'Number of blocks used by the uncompressed sample of the object : ' || l_blkcnt_uncmp); DBMS_OUTPUT.put_line( 'Number of rows in a block in compressed sample of the object : ' || l_row_cmp); DBMS_OUTPUT.put_line( 'Number of rows in a block in uncompressed sample of the object : ' || l_row_uncmp); DBMS_OUTPUT.put_line( 'Estimated Compression Ratio of Sample : ' || l_cmp_ratio); DBMS_OUTPUT.put_line( 'Compression Type : ' || l_comptype_str); END; / Number of blocks used by the compressed sample of the object : 181 Number of blocks used by the uncompressed sample of the object : 481 Number of rows in a block in compressed sample of the object : 551 Number of rows in a block in uncompressed sample of the object : 207 Estimated Compression Ratio of Sample : 2.6 Compression Type : "Compress Advanced" PL/SQL procedure successfully completed.
Não vou entrar no detalhe de cada parâmetro da procedure, mas basicamente passamos o owner, a tabela, e a constante com a compressão desejada (no parâmetro comptype. A constante DBMS_COMPRESSION.COMP_ADVANCED representa o Advanced Row Compression) para termos uma estimativa da compressão alcançada. Para mais detalhes da procedure, clique aqui.
Analisando os dados, podemos ver que para a amostra utilizada pelo advisor, temos uma redução de 481 data blocks do objeto não comprimido para 181 data block com a compressão. O número de linhas por bloco também aumenta consideravelmente, de 207 no objeto não comprimido para 551 utilizando a compressão. Podemos também calcular o ganho de espaço através do Compression Ratio, usando a fórmula:
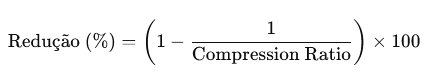
Para o nosso caso, usado o valor 2.6, obtemos uma redução de 61,54%:

Bom, agora vamos à prova real, populando os dados da tabela onde o Advanced Row Compression foi habilitado e realizando as análises:
SQL> INSERT INTO COMPRESSED SELECT * FROM SH.SALES FETCH FIRST 100000 ROWS ONLY;
100000 rows created.
SQL> COMMIT;
Commit complete.
SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname => 'TIAGO', tabname => 'COMPRESSED');
PL/SQL procedure successfully completed.
SQL> EXEC DBMS_STATS.GATHER_TABLE_STATS(ownname => 'TIAGO', tabname => 'NOCOMPRESSED');
PL/SQL procedure successfully completed.
SQL> SELECT TABLE_NAME, BLOCKS, BLOCKS*8 AS TAM_KB FROM DBA_TABLES WHERE TABLE_NAME IN ('COMPRESSED','NOCOMPRESSED');
TABLE_NAME BLOCKS TAM_KB
--------------- ---------- ----------
COMPRESSED 244 1952
NOCOMPRESSED 496 3968
Realizando a comparação do número de blocos por tabela, e fazendo uma aproximação considerando que todos os data blocks de 8KB estão cheios, temos uma redução de 50,8% no tamanho da tabela comprimida em relação à não comprimida. Interessantíssimo o resultado, mesmo com o resultado ficando abaixo do que o advisor nos mostrou.
O que acontece no data block: uma análise mais profunda
Aqui começa a escovação de bits. Para fins práticos de dia a dia dificilmente vamos usar os passos a seguir, mas é interessante ver como a coisa funciona num nível mais baixo.
Aqui vamos analisar o conteúdo de um data block da tabela não comprimida, e em seguida um da tabela comprimida, para vermos a diferença entre eles, e o que faz com que um data block contenha mais linhas que o outro.
Para isso, vamos precisar de dois dados: o file ID dos data files das tablespaces criadas e o número do data block de uma determinada linha. Podemos pegar esses dados com as consultas:
SQL> SELECT FILE_ID, TABLESPACE_NAME FROM DBA_DATA_FILES WHERE TABLESPACE_NAME LIKE '%COMP%';
FILE_ID TABLESPACE_NAME
---------- ------------------------------
15 TBS_NOCOMPRESS
16 TBS_COMPRESS
SQL> SELECT * FROM COMPRESSED WHERE TIME_ID = TO_DATE('20/01/2019','DD/MM/YYYY') FETCH FIRST 1 ROW ONLY;
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- --------- ---------- ---------- ------------- -----------
41 5644 20-JAN-19 3 999 1 47.45
SQL> SELECT * FROM NOCOMPRESSED WHERE TIME_ID = TO_DATE('20/01/2019','DD/MM/YYYY') FETCH FIRST 1 ROW ONLY;
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- --------- ---------- ---------- ------------- -----------
41 5644 20-JAN-19 3 999 1 47.45
SQL> SELECT DBMS_ROWID.ROWID_BLOCK_NUMBER(row_id => ROWID) BLOCK_NUMBER FROM NOCOMPRESSED WHERE TIME_ID = TO_DATE('20/01/2019','DD/MM/YYYY') FETCH FIRST 1 ROW ONLY;
BLOCK_NUMBER
------------
195
SQL> SELECT DBMS_ROWID.ROWID_BLOCK_NUMBER(row_id => ROWID) BLOCK_NUMBER FROM COMPRESSED WHERE TIME_ID = TO_DATE('20/01/2019','DD/MM/YYYY') FETCH FIRST 1 ROW ONLY;
BLOCK_NUMBER
------------
153
O filtro da cláusula WHERE das duas tabelas foi pego ao acaso, de uma forma que representasse o mesmo dado inserido em ambas as tabelas. Para verificar o número do data block das linhas, foi usada a função DBMS_ROWID.ROWID_BLOCK_NUMBER.
Agora com os dados coletados, vamos fazer a exportação do conteúdo desses data blocks para arquivos de trace:
SQL> ALTER SYSTEM CHECKPOINT; System altered. -- exportação do data block da tabela não comprimida SQL> ALTER SESSION SET tracefile_identifier = 'nocompress'; Session altered. SQL> ALTER SYSTEM DUMP DATAFILE 15 BLOCK 195; System altered. -- exportação do data block da tabela comprimida SQL> ALTER SESSION SET tracefile_identifier = 'compress'; Session altered. SQL> ALTER SYSTEM DUMP DATAFILE 16 BLOCK 153; System altered.
Os arquivos gerados ficam dentro do diretório de trace do banco:
$ ls /u01/app/oracle/diag/rdbms/orcl/orcl/trace/*compr* /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_31560_compress.trc /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_31560_compress.trm /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_31560_nocompress.trc /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_31560_nocompress.trm
Vamos analisar inicialmente o dump do data block da tabela sem compressão (aqui vou omitir boa parte do dump, mostrando apenas os detalhes importantes para nossa análise). No trace orcl_ora_31560_nocompress.trc, podemos ver o dump do cabeçalho do data block:
Block header dump: 0x03c000c3
Object id on Block? Y
seg/obj: 0x11ede csc: 0x000000000040b498 itc: 2 flg: E typ: 1 - DATA
brn: 0 bdba: 0x3c000c0 ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x000a.008.000002f5 0x02414036.00eb.05 --U- 212 fsc 0x0000.0040b5e0
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
bdba: 0x03c000c3
data_block_dump,data header at 0x8e500064
===============
tsiz: 0x1f98
hsiz: 0x1ba
pbl: 0x8e500064
76543210
flag=--------
ntab=1
nrow=212
frre=-1
fsbo=0x1ba
fseo=0x4ee
avsp=0x334
tosp=0x334
0xe:pti[0] nrow=212 offs=0
0x12:pri[0] offs=0x1467
0x14:pri[1] offs=0x1487
0x16:pri[2] offs=0x14a7
0x18:pri[3] offs=0x14c7
0x1a:pri[4] offs=0x14e7
0x1c:pri[5] offs=0x1507
0x1e:pri[6] offs=0x1527
0x20:pri[7] offs=0x1548
...
0x1ac:pri[205] offs=0x1386
0x1ae:pri[206] offs=0x13a7
0x1b0:pri[207] offs=0x13c7
0x1b2:pri[208] offs=0x13e7
0x1b4:pri[209] offs=0x1407
0x1b6:pri[210] offs=0x1427
0x1b8:pri[211] offs=0x1447
No cabeçalho temos a informação do OBJECT_ID na seção seg/obj: 0x11ede
SQL> select object_name from dba_objects where object_id = 73438; OBJECT_NAME -------------------------------------------------------------------------------- NOCOMPRESSED
Um pouco mais abaixo temos a informação ntab=1, que indica que temos uma tabela neste data block, o que faz bastante sentido, já que um data block pertence a um extent que pertence a um segmento. Logo abaixo temos nrow=212, que indica que 212 linhas estão contidas no bloco.
Logo abaixo, temos o table directory e o row directory, onde a entrada 0xe:pti[0] nrow=212 offs=0 indica a posição da linha inicial do objeto e quantas linhas ele tem no bloco. Podemos notar que as linhas logo abaixo possuem um endereço e um offset, que fazem com que o Oracle identifique onde ele precisa buscar o dado dentro do bloco quando solicitado. Além disso, o range das linhas vai de 0 a 211, totalizando as 212 linhas do data block, conforme o indicado.
Agora vamos para a parte seguinte do data block, que armazena os dados:
tab 0, row 0, @0x1467 tl: 32 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 2] c1 18 col 1: [ 3] c2 46 0e col 2: [ 7] 78 77 06 1e 01 01 01 col 3: [ 2] c1 04 col 4: [ 3] c2 0a 64 col 5: [ 2] c1 02 col 6: [ 3] c1 18 4c tab 0, row 1, @0x1487 tl: 32 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 2] c1 18 col 1: [ 3] c2 47 57 col 2: [ 7] 78 77 06 1e 01 01 01 col 3: [ 2] c1 04 col 4: [ 3] c2 0a 64 col 5: [ 2] c1 02 col 6: [ 3] c1 18 4c tab 0, row 2, @0x14a7 tl: 32 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 2] c1 18 col 1: [ 3] c2 53 25 col 2: [ 7] 78 77 06 1e 01 01 01 col 3: [ 2] c1 04 col 4: [ 3] c2 0a 64 col 5: [ 2] c1 02 col 6: [ 3] c1 18 4c ... tl: 32 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 2] c1 2b col 1: [ 3] c2 11 12 col 2: [ 7] 78 77 02 0c 01 01 01 col 3: [ 2] c1 04 col 4: [ 3] c2 0a 64 col 5: [ 2] c1 02 col 6: [ 3] c1 30 2e tab 0, row 211, @0x1447 tl: 32 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 2] c1 2b col 1: [ 3] c2 11 52 col 2: [ 7] 78 77 02 0c 01 01 01 col 3: [ 2] c1 04 col 4: [ 3] c2 0a 64 col 5: [ 2] c1 02 col 6: [ 3] c1 30 2e end_of_block_dump End dump data blocks tsn: 7 file#: 15 minblk 195 maxblk 195
Como visto no comando DESCRIBE da tabela, temos 7 (sete) colunas que estão representadas nos registros de cada linha. Essa informação também é mostrada no item column count da linha: cc: 7.
No cabeçalho da linha, temos algumas informações como tl: 32, o total length, indicando uma linha de 32 bytes, fb: --H-FL-- indicando flags e o lock byte lb: 0x1 usado para a consistência transacional.
A lista das colunas e seus valores vem logo abaixo, e os valores entre colchetes indicam o tamanho em bytes da linha. Por exemplo a col 2 tem 7 bytes de tamanho, já que armazena dados da coluna TIME_ID do tipo DATE.
Agora que já vimos um pouco do nosso data block sem compressão, vamos partir para o data block com compressão, através do trace orcl_ora_31560_compress.trc, iniciando pelo cabeçalho:
Block header dump: 0x04000099
Object id on Block? Y
seg/obj: 0x11edf csc: 0x000000000040b5bd itc: 2 flg: E typ: 1 - DATA
brn: 1 bdba: 0x4000090 ver: 0x01 opc: 0
inc: 0 exflg: 0
Itl Xid Uba Flag Lck Scn/Fsc
0x01 0x000a.008.000002f5 0x02414164.00ed.02 --U- 537 fsc 0x0000.0040b5e0
0x02 0x0000.000.00000000 0x00000000.0000.00 ---- 0 fsc 0x0000.00000000
bdba: 0x04000099
data_block_dump,data header at 0x948a8064
===============
tsiz: 0x1f98
hsiz: 0x4e2
pbl: 0x948a8064
76543210
flag=-0----X-
ntab=2
nrow=606
frre=-1
fsbo=0x4e2
fseo=0x9c1
avsp=0x328
tosp=0x328
r0_9ir2=0x1
mec_kdbh9ir2=0x28
76543210
shcf_kdbh9ir2=----------
76543210
flag_9ir2=--R-LNOC Archive compression: N
fcls_9ir2[0]={ }
perm_9ir2[7]={ 2 6 5 3 0 1 4 }
0x1e:pti[0] nrow=69 offs=0
0x22:pti[1] nrow=537 offs=69
0x26:pri[0] offs=0x1e6e
0x28:pri[1] offs=0x1e77
0x2a:pri[2] offs=0x1d34
0x2c:pri[3] offs=0x1e9b
0x2e:pri[4] offs=0x1e92
0x30:pri[5] offs=0x1ead
0x32:pri[6] offs=0x1e36
...
0x4d6:pri[600] offs=0xb83
0x4d8:pri[601] offs=0xba3
0x4da:pri[602] offs=0xbc3
0x4dc:pri[603] offs=0xbe4
0x4de:pri[604] offs=0xc04
0x4e0:pri[605] offs=0xc24
Podemos iniciar verificando que estamos no data block da tabela COMPRESSED, devido à seção seg/obj: 0x11edf, que convertida para número é 73439, que é o OBJECT_ID da nossa tabela:
SQL> select object_name from dba_objects where object_id = 73439; OBJECT_NAME -------------------------------------------------------------------------------- COMPRESSED
Agora o primeiro ponto estranho aqui é ntab=2. Como assim? Eu tenho duas tabelas no mesmo data block? Bom, vamos lembrar do que a compressão no Oracle faz: a criação de uma symbol table, que é armazenada dentro do data block.
A flag 0 (zero) em flag=-0----X- indica que o bloco tem compressão habilitada.
Olhando para o table directory, temos duas entradas: 0x1e:pti[0] nrow=69 offs=0 e 0x22:pti[1] nrow=537 offs=69. Temos 69 linhas armazenadas da nossa symbol table e 537 linhas armazenadas da tabela COMPRESSED.
Pequena pausa da análise do data block pra um comparativo entre o número de linhas armazenadas nos dois cenários: no bloco com compressão temos 537 linhas da nossa tabela, contra 212 que tínhamos no bloco não comprimido. Ou seja, mesmo que o data block com compressão tenha que armazenar a symbol table, ele consegue ter um grande ganho em relação ao bloco sem compressão. E vale citar que dependendo da forma com que os dados se comportam, onde muitos valores são repetidos, o ganho pode ser muito maior. Outra observação: o advisor teve uma margem de erro pequena na estimativa de linhas inseridas por blocos:
Number of rows in a block in compressed sample of the object : 551 --> real 537 Number of rows in a block in uncompressed sample of the object : 207 --> real 212
Obviamente estamos analisando um bloco apenas, e o panorama geral pode ser diferente, mas ainda assim é algo que precisa ser citado.
Voltando ao bloco, agora temos uma parte do cabeçalho que não vimos no data block não comprimido:
r0_9ir2=0x1
mec_kdbh9ir2=0x28
76543210
shcf_kdbh9ir2=----------
76543210
flag_9ir2=--R-LNOC Archive compression: N
fcls_9ir2[0]={ }
perm_9ir2[7]={ 2 6 5 3 0 1 4 }
O ponto interessante aqui é que o Oracle reorganiza as colunas da tabela principal na symbol table, conforme a ordem mostrada na seção perm_9ir2[7]={ 2 6 5 3 0 1 4 }. O foco dessa reorganização é atingir uma taxa de compactação maior.
Na parte onde ficam armazenados os dados também temos mudanças:
block_row_dump: tab 0, row 0, @0x1e6e tl: 9 fb: --H-FL-- lb: 0x0 cc: 6 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 24 col 3: [ 2] c1 04 col 4: [ 3] c1 37 11 col 5: [ 7] 78 77 04 10 01 01 01 bindmp: 00 28 06 28 29 2a 2b 3c 3e tab 0, row 1, @0x1e77 tl: 9 fb: --H-FL-- lb: 0x0 cc: 6 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 24 col 3: [ 2] c1 04 col 4: [ 3] c1 39 4e col 5: [ 7] 78 77 04 19 01 01 01 bindmp: 00 20 06 28 29 2a 2b 35 42 tab 0, row 2, @0x1d34 tl: 12 fb: --H-FL-- lb: 0x0 cc: 6 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 2a col 3: [ 2] c1 04 col 4: [ 3] c1 30 2e col 5: [ 7] 78 77 01 1e 01 01 01 bindmp: 00 17 06 25 cf 78 77 01 1e 01 01 01 ... tab 0, row 67, @0x1f48 tl: 10 fb: --H-FL-- lb: 0x0 cc: 1 col 0: [ 7] 78 77 04 0d 01 01 01 bindmp: 00 02 cf 78 77 04 0d 01 01 01 tab 0, row 68, @0x1ee7 tl: 10 fb: --H-FL-- lb: 0x0 cc: 1 col 0: [ 7] 78 77 02 05 01 01 01 bindmp: 00 02 cf 78 77 02 05 01 01 01 tab 1, row 0, @0x1cd1 tl: 8 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 24 col 3: [ 2] c1 03 col 4: [ 3] c1 38 64 col 5: [ 7] 78 77 04 03 01 01 01 col 6: [ 3] c2 19 5a bindmp: 2c 01 02 09 cb c2 19 5a tab 1, row 1, @0x1cc9 tl: 8 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 24 col 3: [ 2] c1 03 col 4: [ 3] c1 38 64 col 5: [ 7] 78 77 04 03 01 01 01 col 6: [ 3] c2 1b 10 bindmp: 2c 01 02 09 cb c2 1b 10 ... tab 1, row 535, @0xc04 tl: 32 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 2b col 3: [ 2] c1 03 col 4: [ 3] c1 2f 50 col 5: [ 7] 78 77 01 1c 01 01 01 col 6: [ 3] c2 10 27 bindmp: 2c 01 07 cb c2 0a 64 ca c1 02 ca c1 2b ca c1 03 cb c1 2f 50 cf 78 77 01 1c 01 01 01 cb c2 10 27 tab 1, row 536, @0xc24 tl: 32 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 2b col 3: [ 2] c1 03 col 4: [ 3] c1 2f 50 col 5: [ 7] 78 77 01 1c 01 01 01 col 6: [ 3] c2 34 07 bindmp: 2c 01 07 cb c2 0a 64 ca c1 02 ca c1 2b ca c1 03 cb c1 2f 50 cf 78 77 01 1c 01 01 01 cb c2 34 07 end_of_block_dump End dump data blocks tsn: 8 file#: 16 minblk 153 maxblk 153
Aqui podemos ver os blocos de duas tabelas armazenados, tab 0, que é a nossa symbol table, e tab 1, a tabela COMPRESSED.
Quando olhamos para as linhas 0 e 1 da tab1, podemos perceber que ambas tem apenas 8 bytes (tl: 8). Nos blocos da nossa tabela NOCOMPRESSED, os blocos tinham 32 bytes de tamanho em média. Essa redução é devido à compressão. Podemos fazer a conta rápida de quanto essa linha teria de tamanho: 22 bytes de dados (soma do tamanho das colunas), 7 bytes do column count, e mais um byte por flag (tl, fb e lb) resultando em 32 bytes de tamanho (22 +7 + 1 + 1 + 1 = 32).
No final da linha podemos ver o campo bindmp, que representa os bytes retornados. No caso da row 0, são 8 bytes sendo retornados na linha. O pulo do gato aqui é que neste retorno estão sendo feitos apontamentos para blocos da symbol table, que contém os dados de fato.
O quão fundo você está disposto a descer na toca do coelho?
Essa é a seção onde vamos sentir falta da simplicidade com que a Oracle traz a symbol table na documentação mostrada no início do post. Vamos começar analisando o bindmp da row 0 da tab 1 (nossa tabela de dados):
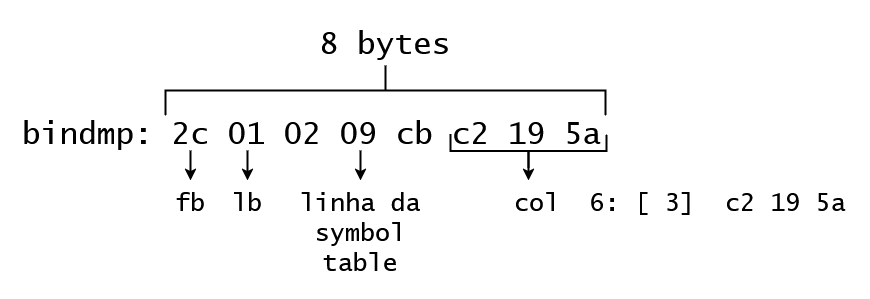
O tamanho total é de 8 bytes, conforme já vimos. O primeiro e o segundo byte corresponde ao flag byte e o lock byte respectivamente. O quarto byte representa a referência feita à symbol table. Os três últimos bytes correspondem aos dados contidos na coluna 6 da linha, ou seja, essa coluna não tem compressão habilitada. O terceiro e o quinto byte não estão explanados aqui pois não encontrei exatamente para que eles servem (nas referências existem algumas citações, mas como se referem a versões mais antigas do Oracle, acredito que não sejam o que temos aqui na versão 19c).
Vamos agora analisar a referência da symbol table. O valor 09 é o código hexadecimal da linha, no caso 9. A linha 9 da symbol table segue abaixo:
tab 0, row 9, @0x1eb6 tl: 9 fb: --H-FL-- lb: 0x0 cc: 6 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 24 col 3: [ 2] c1 03 col 4: [ 3] c1 38 64 col 5: [ 7] 78 77 04 03 01 01 01 bindmp: 00 11 06 28 29 2a 2c 3b 34
Para a symbol table, o bindmp tem bytes com diferentes significados:
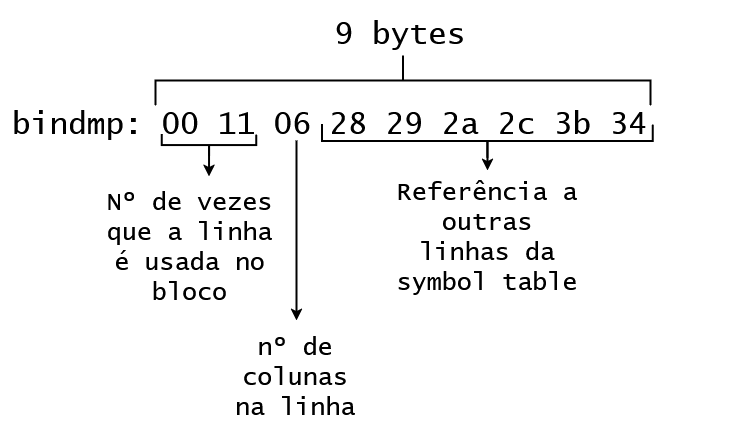
Como temos tl: 9, temos 9 bytes sendo retornados no bindmp. Os dois primeiros mostram o número de vezes que esse token é referenciado. O terceiro byte mostra o número de colunas da linha. Aqui temos o valor 6, pois uma das colunas não possuía compressão no bloco da tabela, conforme vimos anteriormente. Os outros seis bytes são referências a outras linhas da symbol table (sim, entradas da symbol table podem fazer referência a outras linhas da symbol table). Esses endereços são os valores hexadecimais, que devemos converter para encontrar o número da linha onde o dado está:
SQL> SELECT '28 = ' || TO_NUMBER('28', 'XXXXX') AS "CONVERSAO HEX -> DECIMAL" FROM DUAL
UNION ALL
SELECT '29 = ' || TO_NUMBER('29', 'XXXXX') FROM DUAL
UNION ALL
SELECT '2a = ' || TO_NUMBER('2a', 'XXXXX') FROM DUAL
UNION ALL
SELECT '2c = ' || TO_NUMBER('2c', 'XXXXX') FROM DUAL
UNION ALL
SELECT '3b = ' || TO_NUMBER('3b', 'XXXXX') FROM DUAL
UNION ALL
SELECT '34 = ' || TO_NUMBER('34', 'XXXXX') FROM DUAL;
CONVERSAO HEX -> DECIMAL
-----------------------------------------------
28 = 40
29 = 41
2a = 42
2c = 44
3b = 59
34 = 52
6 rows selected.
Pegando as linhas 40, 41, 42, 44, 59 e 52 da symbol table:
tab 0, row 40, @0x1f73 tl: 6 fb: --H-FL-- lb: 0x0 cc: 1 col 0: [ 3] c2 0a 64 bindmp: 00 1a cb c2 0a 64 tab 0, row 41, @0x1f79 tl: 5 fb: --H-FL-- lb: 0x0 cc: 1 col 0: [ 2] c1 02 bindmp: 00 1a ca c1 02 tab 0, row 42, @0x1f7e tl: 5 fb: --H-FL-- lb: 0x0 cc: 1 col 0: [ 2] c1 24 bindmp: 00 0c ca c1 24 tab 0, row 44, @0x1f83 tl: 5 fb: --H-FL-- lb: 0x0 cc: 1 col 0: [ 2] c1 03 bindmp: 00 0a ca c1 03 tab 0, row 59, @0x1f88 tl: 6 fb: --H-FL-- lb: 0x0 cc: 1 col 0: [ 3] c1 38 64 bindmp: 00 03 cb c1 38 64 tab 0, row 52, @0x1f8e tl: 10 fb: --H-FL-- lb: 0x0 cc: 1 col 0: [ 7] 78 77 04 03 01 01 01 bindmp: 00 05 cf 78 77 04 03 01 01 01
Podemos verificar que os últimos bytes do bindmp de cada uma das linhas agora retorna o dado sem a compressão, e a sequência das linhas é a sequência das colunas que vimos na row 9 da symbol table.
Colocando essas associações de uma maneira mais visual temos:
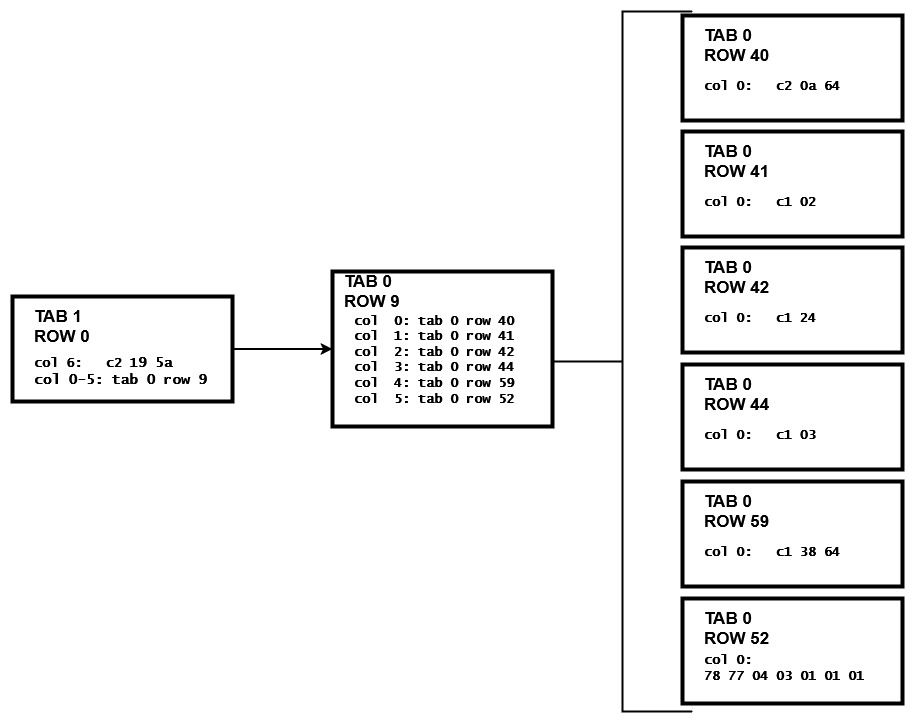
Tirando a prova real
Por mais que eu ache que este post está mais longo que o normal, tem uma última coisa que quero fazer: ver a linha na tabela para esta row. Voltamos a analisar a row 0 da tab 1 novamente:
tab 1, row 0, @0x1cd1 tl: 8 fb: --H-FL-- lb: 0x1 cc: 7 col 0: [ 3] c2 0a 64 col 1: [ 2] c1 02 col 2: [ 2] c1 24 col 3: [ 2] c1 03 col 4: [ 3] c1 38 64 col 5: [ 7] 78 77 04 03 01 01 01 col 6: [ 3] c2 19 5a bindmp: 2c 01 02 09 cb c2 19 5a
Como a documentação descreve, os dados da tabela geralmente são armazenados na ordem do comando CREATE TABLE, mas a ordem não é garantida. Podemos analisar a estrutura da tabela:
SQL> DESC COMPRESSED Name Null? Type ----------------------------------------- -------- ---------------------------- PROD_ID NOT NULL NUMBER(6) CUST_ID NOT NULL NUMBER TIME_ID NOT NULL DATE CHANNEL_ID NOT NULL NUMBER(1) PROMO_ID NOT NULL NUMBER(6) QUANTITY_SOLD NOT NULL NUMBER(3) AMOUNT_SOLD NOT NULL NUMBER(10,2)
De cara podemos dizer que a ordem da row piece não segue a ordem da tabela, pois temos na col 5 a coluna de 7 bytes que remete à data. Algo que pode nos ajudar a identificar os dados e então identificar as colunas é a DBMS_STATS.CONVERT_RAW_VALUE:
SQL> SET SERVEROUTPUT ON
DECLARE
RV1 RAW(32) := 'c20a64';
RV2 RAW(32) := 'c102';
RV3 RAW(32) := 'c124';
RV4 RAW(32) := 'c103';
RV5 RAW(32) := 'c13864';
RV6 RAW(32) := '78770403010101';
RV7 RAW(32) := 'c2195a';
NB1 NUMBER;
NB2 NUMBER;
NB3 NUMBER;
NB4 NUMBER;
NB5 NUMBER;
NB6 NUMBER;
DT1 DATE;
BEGIN
DBMS_STATS.CONVERT_RAW_VALUE(RV1, NB1);
DBMS_STATS.CONVERT_RAW_VALUE(RV2, NB2);
DBMS_STATS.CONVERT_RAW_VALUE(RV3, NB3);
DBMS_STATS.CONVERT_RAW_VALUE(RV4, NB4);
DBMS_STATS.CONVERT_RAW_VALUE(RV5, NB5);
DBMS_STATS.CONVERT_RAW_VALUE(RV6, DT1);
DBMS_STATS.CONVERT_RAW_VALUE(RV7, NB6);
DBMS_OUTPUT.put_line( 'col 0: ' || NB1);
DBMS_OUTPUT.put_line( 'col 1: ' || NB2);
DBMS_OUTPUT.put_line( 'col 2: ' || NB3);
DBMS_OUTPUT.put_line( 'col 3: ' || NB4);
DBMS_OUTPUT.put_line( 'col 4: ' || NB5);
DBMS_OUTPUT.put_line( 'col 5: ' || DT1);
DBMS_OUTPUT.put_line( 'col 6: ' || NB6);
END;
/
col 0: 999
col 1: 1
col 2: 35
col 3: 2
col 4: 55.99
col 5: 03-APR-19
col 6: 2489
PL/SQL procedure successfully completed.
A partir destes dados, podemos identificar que a col 5 remete à coluna TIME_ID, a única coluna DATE da tabela, e a col 4 à coluna AMOUNT_SOLD, devido aos decimais encontrados. Como todas as demais são do tipo NUMBER, é difícil dizer qual é cada coluna. Mas podemos executar uma busca filtrando pelas colunas que identificamos:
SQL> SELECT * FROM COMPRESSED WHERE TIME_ID=TO_DATE('03/04/2019','DD/MM/YYYY') AND AMOUNT_SOLD = 55.99;
PROD_ID CUST_ID TIME_ID CHANNEL_ID PROMO_ID QUANTITY_SOLD AMOUNT_SOLD
---------- ---------- --------- ---------- ---------- ------------- -----------
35 2489 03-APR-19 2 999 1 55.99 --> essa é a linha que bate com os valores encontrados
35 2615 03-APR-19 2 999 1 55.99
35 2935 03-APR-19 2 999 1 55.99
35 3035 03-APR-19 2 999 1 55.99
35 3058 03-APR-19 2 999 1 55.99
35 3842 03-APR-19 2 999 1 55.99
35 3872 03-APR-19 2 999 1 55.99
35 4006 03-APR-19 2 999 1 55.99
35 4897 03-APR-19 2 999 1 55.99
35 5583 03-APR-19 2 999 1 55.99
35 6961 03-APR-19 2 999 1 55.99
35 7087 03-APR-19 2 999 1 55.99
35 8623 03-APR-19 2 999 1 55.99
35 11124 03-APR-19 2 999 1 55.99
35 11575 03-APR-19 2 999 1 55.99
35 12743 03-APR-19 2 999 1 55.99
35 13493 03-APR-19 2 999 1 55.99
35 218 03-APR-19 2 999 1 55.99
35 1622 03-APR-19 2 999 1 55.99
35 1657 03-APR-19 2 999 1 55.99
35 1823 03-APR-19 2 999 1 55.99
35 2144 03-APR-19 2 999 1 55.99
Como podemos ver acima, a primeira linha retornada corresponde a todos os valores encontrados. Sendo assim temos:
col 0: PROMO_ID col 1: QUANTITY_SOLD col 2: PROD_ID col 3: CHANNEL_ID col 4: AMOUNT_SOLD col 5: TIME_ID col 6: CUST_ID
Neste caso os dados contidos na linha do data block não correspoderam à ordem das colunas na tabela.
Para fechar, podemos coletar os dados da localização da linha, utilizando a DBMS_ROWID.ROWID_INFO:
SQL> DECLARE
v_rowid ROWID;
v_rowid_type NUMBER;
v_data_object NUMBER;
v_file_number NUMBER;
v_block_number NUMBER;
v_row_number NUMBER;
BEGIN
SELECT ROWID INTO v_rowid FROM COMPRESSED WHERE CUST_ID=2489 AND TIME_ID=TO_DATE('03/04/2019','DD/MM/YYYY') AND AMOUNT_SOLD = 55.99;
DBMS_ROWID.ROWID_INFO(
rowid_in => v_rowid,
rowid_type => v_rowid_type,
object_number => v_data_object,
relative_fno => v_file_number,
block_number => v_block_number,
row_number => v_row_number
);
DBMS_OUTPUT.PUT_LINE('Rowid : ' || v_rowid);
DBMS_OUTPUT.PUT_LINE('Rowid Type : ' || v_rowid_type);
DBMS_OUTPUT.PUT_LINE('Object Number: ' || v_data_object);
DBMS_OUTPUT.PUT_LINE('File Number : ' || v_file_number);
DBMS_OUTPUT.PUT_LINE('Block Number : ' || v_block_number);
DBMS_OUTPUT.PUT_LINE('Row Number : ' || v_row_number);
END;
/
Object Number: 73439
File Number: 16
Block Number: 153
Row Number: 0
PL/SQL procedure successfully completed.
Voilà! Temos o Object ID da nossa tabela, o número do data file da tablespace, o número do data block e o número da linha para a nossa tabela.
Conclusão
Chegamos, enfim, ao fim. Espero que tenham tido uma compreensão mais profunda de como funciona o Advanced Row Compression, embora a profundidade que alcançamos neste artigo não seja algo que vamos precisar elaborar no nosso dia a dia.
Caso você ache interessante, vou deixar algumas das referências para este artigo abaixo. Dentre elas, a que eu mais recomendo, é o vídeo do Connor fazendo a análise da estrutura interna do data block. Nesse vídeo ele explora coisas além do vimos aqui.
- Análise do formato do bloco de dados da tabela compactada Oracle, parte I;
- Análise do formato de bloco de da da da da da tabela compactada Oracle, parte II;
- Compression in Oracle – Part 1: Basic Table Compression;
- A tour of the Oracle Database Block;
Um forte abraço a todos!
Publicar comentário