Sobre RAG e Vector Stores
Há algum tempo que penso em escrever sobre Vector Search aqui no blog, e acredito que a melhor forma de começar seja com uma pequena introdução sobre RAG e Vector Stores. Sem essa base, postar sobre a parte mais avançada da coisa não faz sentido nenhum, já que a grande maioria da audiência não tem a presença desse tipo de workload no seu dia a dia (acredito eu, me conte nos comentários se você já tem projetos desse tipo no seu dia a dia).
O que são Vector Stores?
Vector Stores ou Vector Databases são bancos de dados que armazenam vetores. Simple as this. Dentro desse contexto, os vetores são representações matemáticas de algo, como um texto, imagem ou áudio, por exemplo.
Existem diversos Vector Stores, alguns que ganharam popularidade justamente nesse hype sobre IA que estamos vivendo, como FAISS, Pinecone, Milvus ou Annoy, e outros mais tradicionais, como o PostgreSQL, que implementa a funcionalidade de Vector Store através da extensão pgvector, o MongoDB Atlas, e o Oracle Database 23ai (que inclusive mudou sua nomenclatura de 23c para 23ai, justamente devido às novas implementações voltadas à IA).
O que diferencia um Vector Store de um banco de dados “tradicional” é que ele possui funcionalidades que nos permitem trabalhar melhor com esses vetores, e realizar operações que antes não eram tão simples a nível de banco de dados, como, por exemplo, uma Similarity Search (mais à frente falarei sobre ela).
O que é RAG?
RAG é a sigla para Retrieval Augmented Generation (geração aumentada de recuperação, em tradução livre. E sim, a tradução é horrível), e serve para melhorar as capacidades dos modelos LLM. E por que aumentar as capacidades de um LLM? Bom, os LLMs são treinados com uma quantidade enorme de dados históricos, abertos ao público (como publicações na internet), mas não tem acesso a dados mais novos ou dados privados, documentações internas de empresas por exemplo, e isso leva a situações onde o modelo acaba gerando informações incorretas (as ditas alucinações). Com o RAG podemos fornecer contexto extra para o LLM e fazer com que ele tenha acesso a novas informações para que a geração seja mais assertiva.
E então como fornecemos esse contexto adicional? Bom, iniciamos com a fase de indexação de informações. Abaixo temos a representação de uma pipe de indexação:
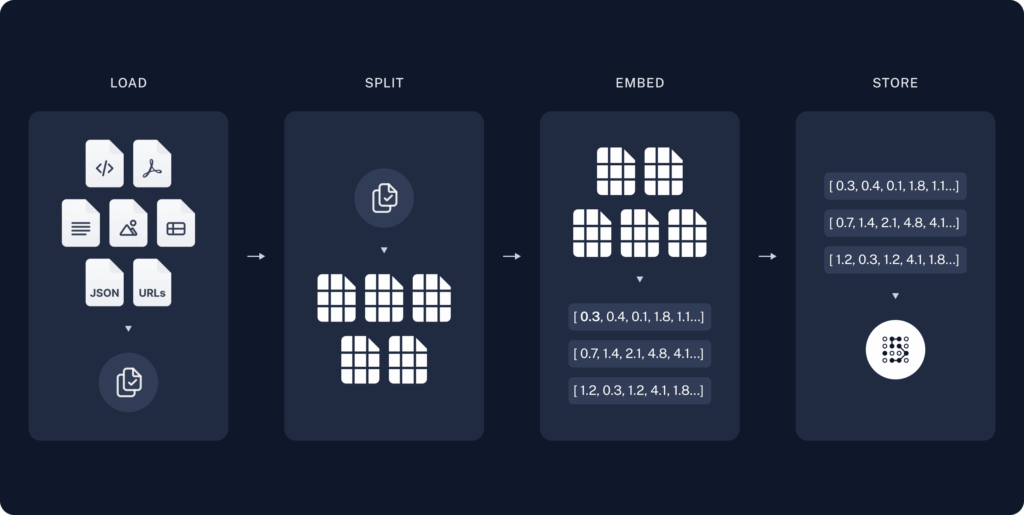
Fonte: LangChain
Inicialmente a aplicação responsável pela indexação realiza a carga de fontes de dados, que podem ser imagens, documentos, aúdios, etc. Em seguida, ela realiza um split da fonte de dados, quebrando ele em segmentos menores. Um exemplo de split de um PDF, seria quebrar o PDF em parágrafos. Isso é feito para que quando o LLM acesse esse pedaço de informação, um contexto mais específico seja lido. Na fase seguinte, de embedding, é onde os vetores são gerados. São fornecidos os pedaços de informação gerados na fase de split a um modelo de embedding, e ele retorna um vetor que corresponde àquela informação. O tamanho do vetor irá depender do modelo de embedding utilizado. Por exemplo, o modelo text-embedding-3-small da OpenAI gera vetores de 1536 dimensões, enquanto o modelo text-embedding-3-large gera vetores com 3072 dimensões. E por fim, na fase de armazenamento é que entram os nossos Vector Stores, que irão guardar a informação para que ela seja utilizada pelo LLM.
Além dos vetores em si, também são inseridos no banco metadados que fazem referência ao pedaço retornado, como página do PDF e parágrafo onde a informação está (em alguns casos até mesmo o texto utilizado).
Agora você deve se perguntar: beleza, e como o LLM vai acessar esse dado? Observe o workflow de um RAG simples:
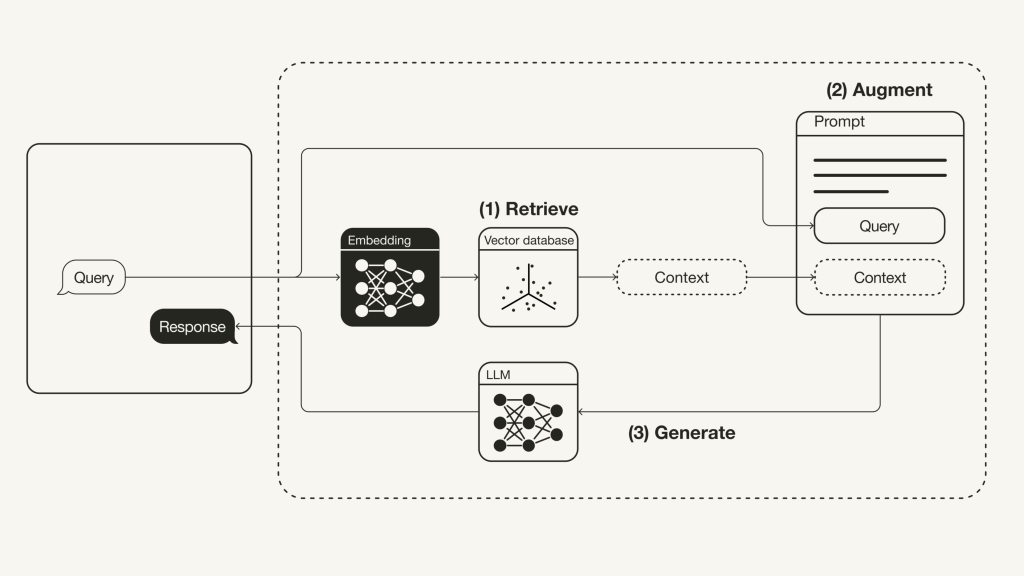
Fonte: Towards Data Science
Inicialmente temos uma query, que em uma aplicação como um chatbot, pode ser a pergunta que o usuário faz para o LLM. Essa query, ou pergunta, nesse caso, passa pelo processo de embedding e é transformada em um vetor, que é comparado com os vetores já armazenados no nosso Vector Store, em um processo chamado de Similarity Search. Nele, uma consulta é realizada no banco de dados, buscando pelos top-N vetores mais próximos daquele gerado pela query de input.
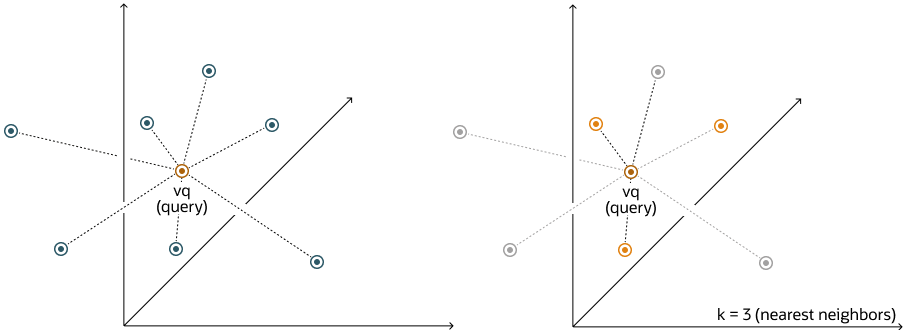
Fonte: Oracle
Com os resultados mais próximos retornados, as linhas são enviadas juntamente com a query do usuário para um prompt, que será enviado ao LLM. Neste fase é que podemos notar o porquê de “Augment” estar na sigla RAG: além da pergunta do usuário, estamos fornecendo contexto a mais para que o LLM tenha mais embasamento para dar a resposta.
Por fim a fase de geração ocorre, onde o LLM recebe o contexto e a questão do usuário, e gera uma resposta mais confiável e alinhada com o contexto que foi passado a ela.
Conclusão
Com a grande repercussão que envolve o tema de IAs generativas, Vector Stores são o que temos de mais quente na área de banco de dados atualmente. Entender como eles se encaixam no fluxo de aplicações baseadas em IA e dominar esse novo contexto de banco de dados é fundamental. A IA veio para ficar, isso é fato, e cada vez mais teremos aplicações utilizando esse tipo de funcionalidade, por isso é bom estarmos preparados. Agora, se a IA vai ou não roubar os nossos empregos, é cena dos próximos capítulos.
Caso tenha interesse em ver uma implementação de um RAG em Python, recomendo a leitura do artigo da Towards Data Science sobre RAG: Retrieval-Augmented Generation (RAG): From Theory to LangChain Implementation.
Em próximos posts estarei trazendo exemplos mais práticos sobre Vector Search. Até a próxima!
4 comments