

No meu artigo “Sobre RAG e Vector Stores” eu introduzi como funciona um fluxo RAG conceitualmente, e agora vou trazer uma abordagem mais prática. Para implementação do fluxo RAG, estou utilizando Python com Langchain, um framework de código aberto para desenvolvimento de aplicações baseadas em LLM, e o Oracle Autonomous Database como Vector Store.
O fluxo implementado lê alguns PDFs de um diretório, os quebra em pedaços menores e gera vetores a partir deles. Para a geração dos vetores (processo de embedding) a API da OpenAI é usada, e então o fluxo insere os vetores gerados no Autonomous Database. Esses vetores são utilizados como contexto adicional para o LLM responder às perguntas que são feitas.
Para rodar esses testes utilizei um notebook Jupyter no Google Colab, e deixei todo o código usado no meu GitHub para não poluir muito o post aqui.
Preparação do ambiente
Para a execução é necessário criar os seguintes diretórios no Colab:
# pwd /content # mkdir wallet # mkdir pdfs
Para o diretório wallet são enviados os arquivos da wallet do Autonomous Database e para o diretório pdfs são enviados os PDFs que servirão como base de conhecimento para a LLM. No meu caso, realizei o upload de duas documentações do Oracle Database: Database Development Guide e o Security Guide.
No diretório também é criado um arquivo .env que irá armazenar as seguintes informações:
DB_USER="user" DB_PASSWORD="password" CONNECT_STRING='string' OPENAI_API_KEY="api-key" WALLET_PASSWORD="autonomous-wallet-password"
Essas informações serão carregadas como variáveis de ambiente para que não fiquem expostas diretamente no código.
Criando os chunks
Depois de realizar a instalação das dependências, e criar as funções, o primeiro passo é realizar a quebra dos PDFs em pedaços menores. Essa fase é necessária para que o limite de input tokens do modelo de embedding não seja ultrapassado (e um erro seja gerado) e também para melhorar o contexto para a LLM. Assim a LLM consegue acessar apenas um parágrafo relevante do documento, por exemplo. No meu caso, os dois PDFs foram quebrados em 4896 chunks:

Cada chunk gerado é um objeto Document que possui metadados, como página e título do PDF para aquele chunk, e um page_content, que possui o texto daquele pedaço:
Inserindo na Vector Store
Para a geração dos embeddings e sua inserção no Oracle Autonomous Database, duas funções são utilizadas: get_vector_database e ingest_pdf_chunks.
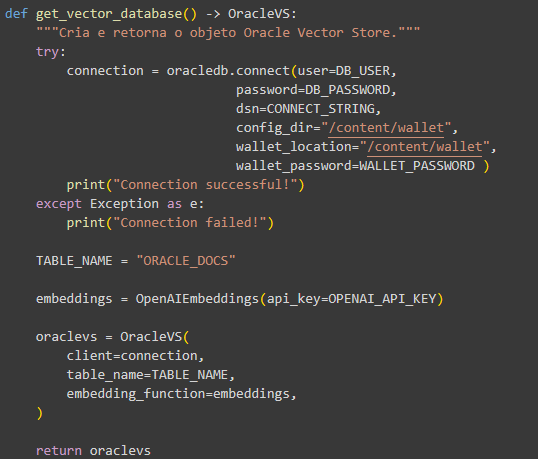
A get_vector_database cria uma conexão com o Autonomous usando os dados do arquivo .env e da wallet, retornando um objeto OracleVS (Oracle Vector Store). Para esse objeto também são repassados o nome da tabela na qual serão inseridos os vetores e o objeto gerador de embeddings, nesse caso o da OpenAI.
Essa função é usada na ingest_pdf_chunks, que utiliza o objeto OracleVS retornado para inserir uma lista de chunks passada por parâmetro.
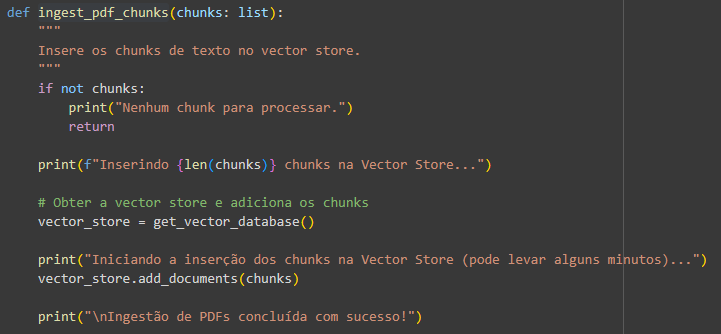
Rodando essa função:

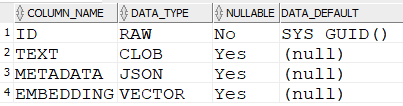
Com essa execução, o Langchain cria uma tabela com o nome definido em get_vector_database no schema usado na conexão, que tem a seguinte estrutura:
No Performance Hub na OCI, podemos ver a operação executada:
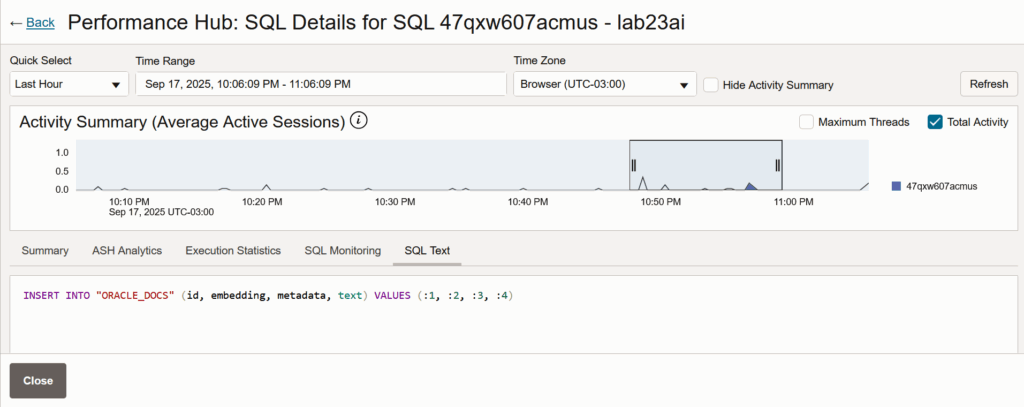
Na tabela criada, é possível observar a dimensão e o formato dos vetores gerados, usando as funções VECTOR_DIMENSION_COUNT e VECTOR_DIMENSION_FORMAT:
SELECT VECTOR_DIMENSION_COUNT(embedding) as dimensions,
VECTOR_DIMENSION_FORMAT(embedding) as format
FROM ORACLE_DOCS
FETCH FIRST 1 ROW ONLY;
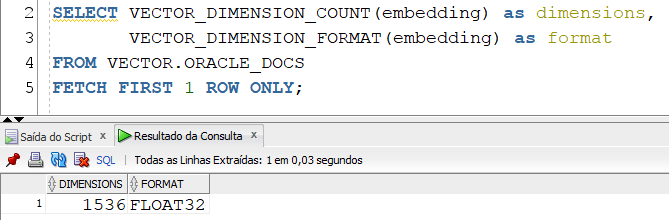
Para este caso, os embeddings gerados pela OpenAI possuem 1536 dimensões e formato FLOAT32.
Realizando consultas
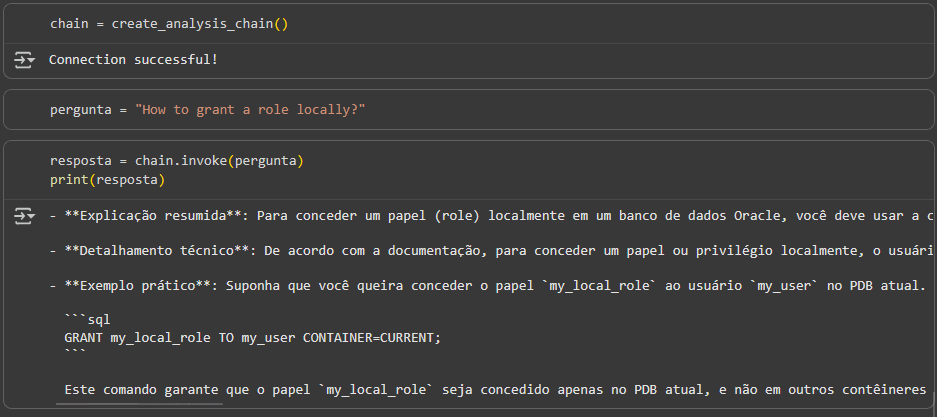
Para que seja possível fazer perguntas para uma LLM e fazer com que ela tenha acesso à nossa base de dados, precisamos criar uma RAG chain, que é o que a função create_analysis_chain faz. Nela a vector store é usada como retriever, que vai buscar os top-N vetores mais relevantes da tabela, com base na pergunta feita pelo usuário. Nesta chain também são definidos o LLM usado, nesse caso o GPT-4o, e o prompt template, onde são inseridos a pergunta do usuário e o resultado da busca vetorial.
Abaixo o trecho onde a chain é definida e uma pergunta é repassada a ela, que será respondida com base nos documentos retirados da base vetorial:
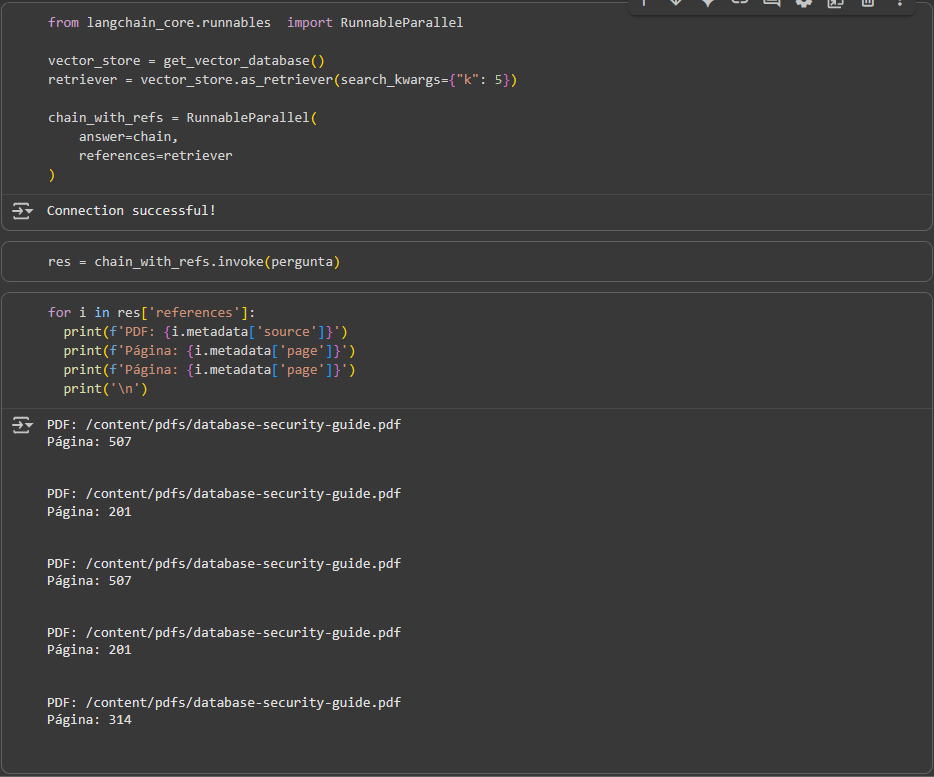
Para entender quais são as referências usadas para a resposta, podemos executar a chain e o retriever com o RunnableParallel, que junta o resultado das chamadas da chain e do retriever em um dicionário só:
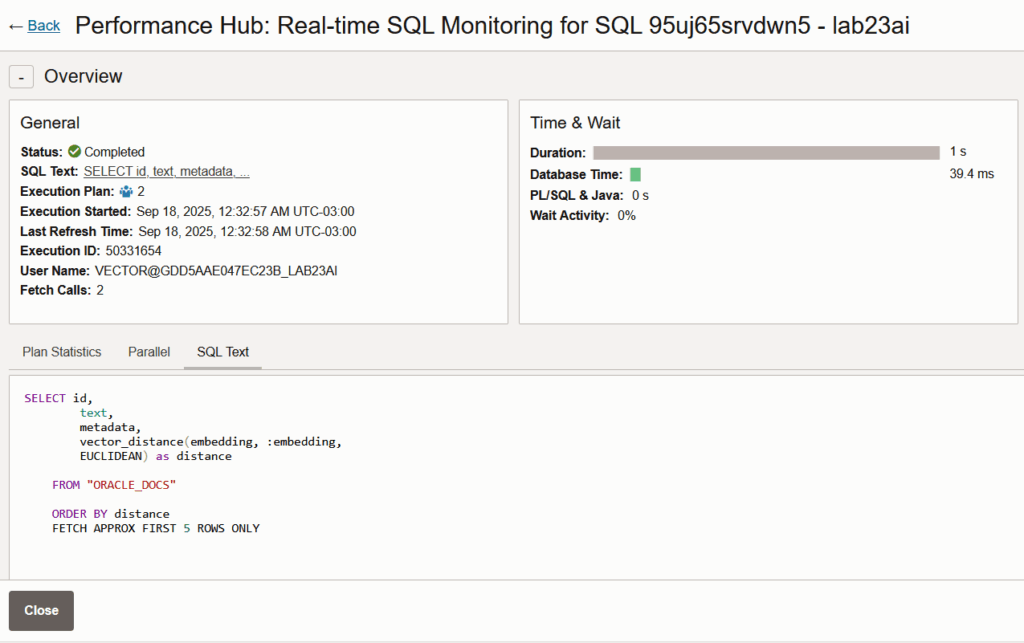
De volta ao Performance Hub, podemos ver a query que o Langchain executa no banco para buscar os top-N vetores mais relevantes:
Se alterarmos a pergunta, podemos ver que os documentos acessados agora fazem referência à outra documentação:
Por fim, eu quis fazer alguns testes, para verificar as distâncias sendo retornadas para cada linha. Para isso decidi escrever uma query personalizada para isso. Antes porém, é necessário gerar o vetor da pergunta, que será repassado via bind para o banco. A utilização do Python ajuda aqui, pois caso esse teste seja feito com o SQL Developer, repassando o vetor como um literal, o erro ORA-01704: “The string literal is longer than 4000 characters” ocorre. Para gerar o vetor da pergunta e salvá-lo em uma variável:

Em seguida, executando a consulta repassando o vetor para a consulta através de uma bind variable:
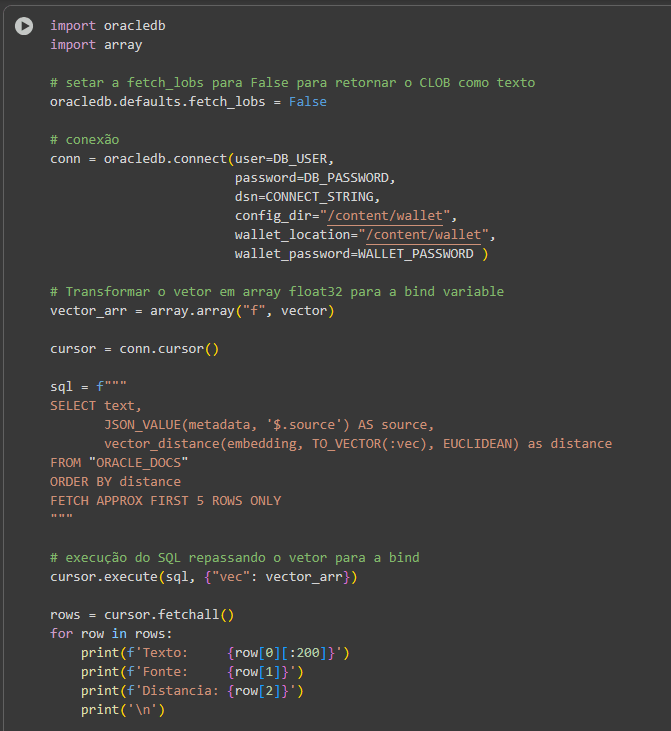
O resultado:
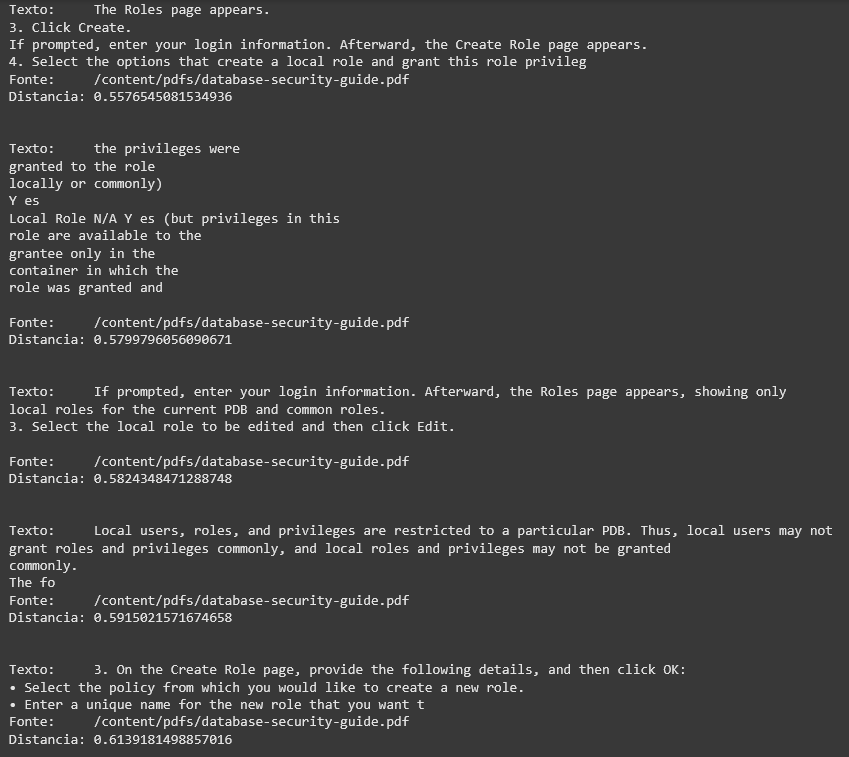
Como podemos perceber, a consulta retorna os resultados ordenados pela distância, sendo os menores valores aqueles cujo contexto é mais relevante em relação à pergunta feita.
Conclusão
Essa é a implementação de um flxuo RAG simples para fins de teste no Oracle Database 23ai, e não usa das melhores práticas para um ambiente produtivo. Por exemplo, não utilizei uma abordagem otimizada de geração de chunks, e fiz a partir do PDF puro mesmo, o que pode não ser a melhor alternativa, uma vez que esses PDFs contém tabelas e outras estruturas que não são traduzidas muito bem em texto. Geralmente, em aplicações reais existe um tratamento das informações do PDF, jogando para outro formato, como Markdown, por exemplo, para que a LLM tenha retornos melhores com informações menos poluídas.
Lembrando que todo o código usado no post está no GitHub e você pode copiar o notebook do Google Colab para realizar seus próprios testes.
Em um próximo artigo, vamos usar essa mesma base para realizar a indexação vetorial.