

A indexação sempre é um tema importante quando pensamos em performance dentro de banco de dados, e não é diferente quando trabalhamos com vetores. Nessa série de artigos sobre índices vetoriais, vou falar um pouco sobre as principais diferenças entre os índices “tradicionais” e os índices vetoriais, sua implementação e funcionamento. Vamos começar aprofundando no funcionamento do Inverted File Flat Index.
Antes disso, é necessário entender os conceitos de Exact Search e Approximate Search. Se você ainda não os conhece, escrevi este artigo sobre o tema: Exact vs Approximate Search no Oracle Database.
O que é um Inverted File Flat Index?
Um Inverted File Flat Index é uma técnica criada para acelerar consultas vetoriais, diminuindo a área de busca dentro do espaço vetorial. Basicamente, durante a sua criação, o espaço vetorial (o conjunto de todos os vetores da coluna indexada) é separado em clusters (partições) e um centróide é calculado para cada cluster. Esses centróides são vetores que representam o “ponto central” de cada cluster gerado. Na imagem abaixo, os vetores são representados pelo “X” e os centróides são representados pelo ponto:
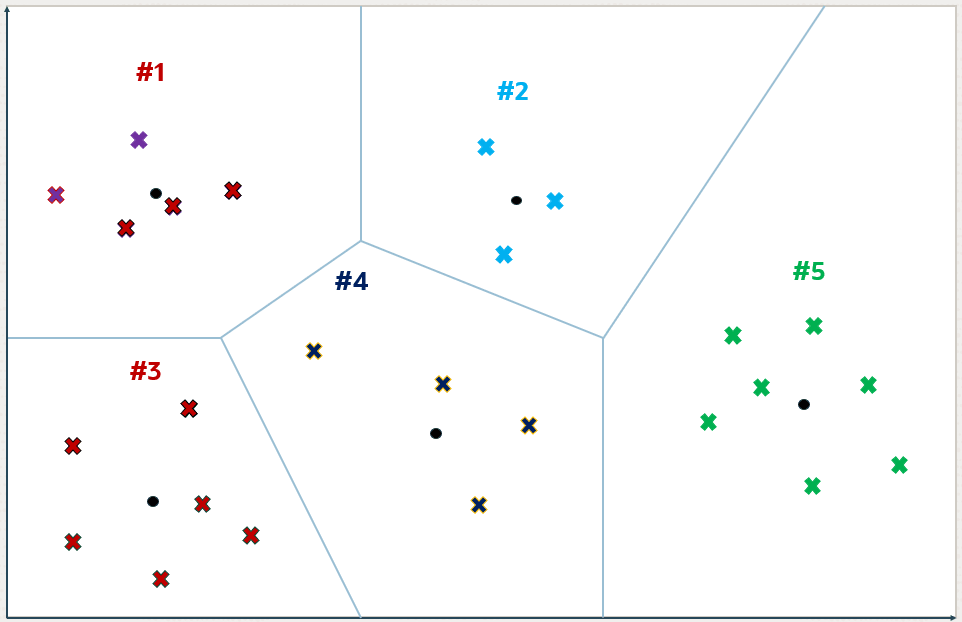
Geralmente o número de partições é definido como sendo a raiz quadrada do número total de vetores no espaço vetorial. Esse número pode ser alterado com o parâmetro NEIGHBOR PARTITIONS do comando de criação do índice IVF no Oracle. No próximo post dessa série veremos esse comando em ação.
Busca vetorial com Inverted File Flat Index
Como falei no post sobre Approximate Search, quando passamos a usar índices vetorias, nossa precisão diminui, e agora vamos entender o porquê isso ocorre quando usamos o Inverted File Flat Index.
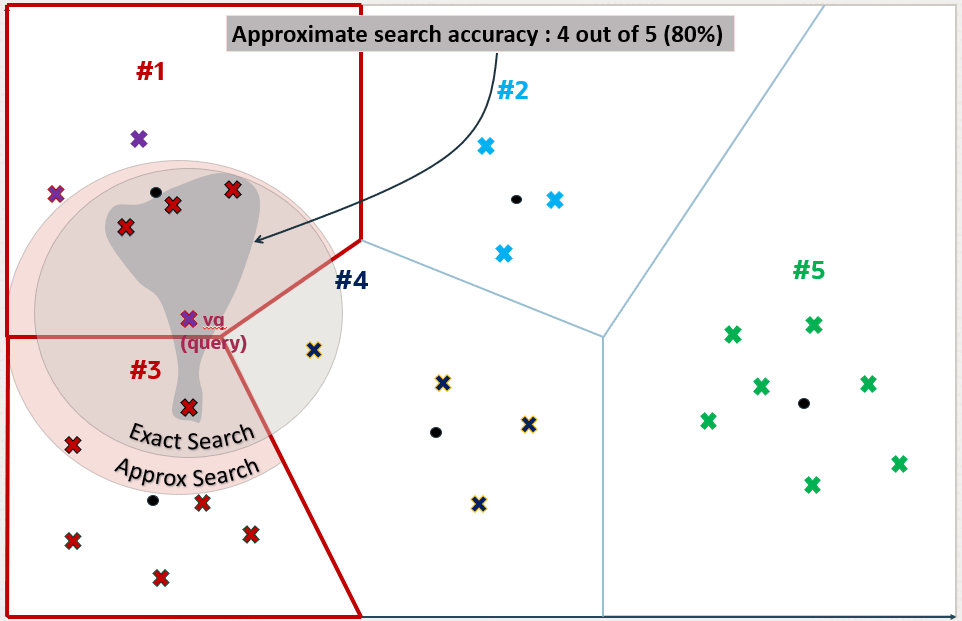
Como sabemos, quando uma busca vetorial é feita, um vetor é passado da aplicação para o banco, que geralmente é o embedding gerado a partir da interação do usuário com a aplicação, como um prompt, por exemplo (vetor vq na figura abaixo).
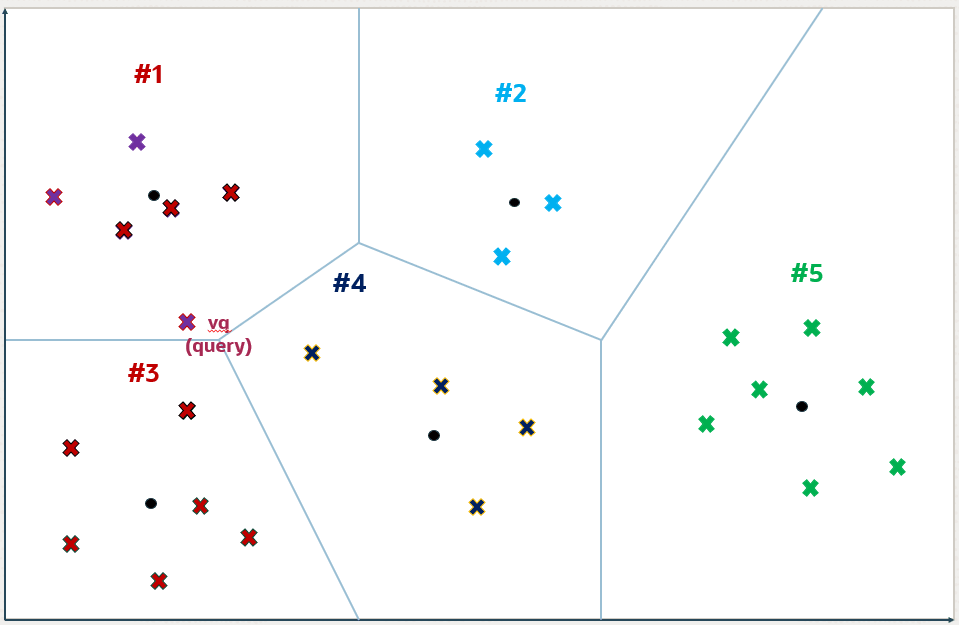
Esse vetor é enviado para o banco em uma consulta que pretende buscar os top-k vetores mais próximos. Nessa primeira fase da consulta, o banco irá calcular a distância entre o vetor passado na consulta e os centróides do índice.
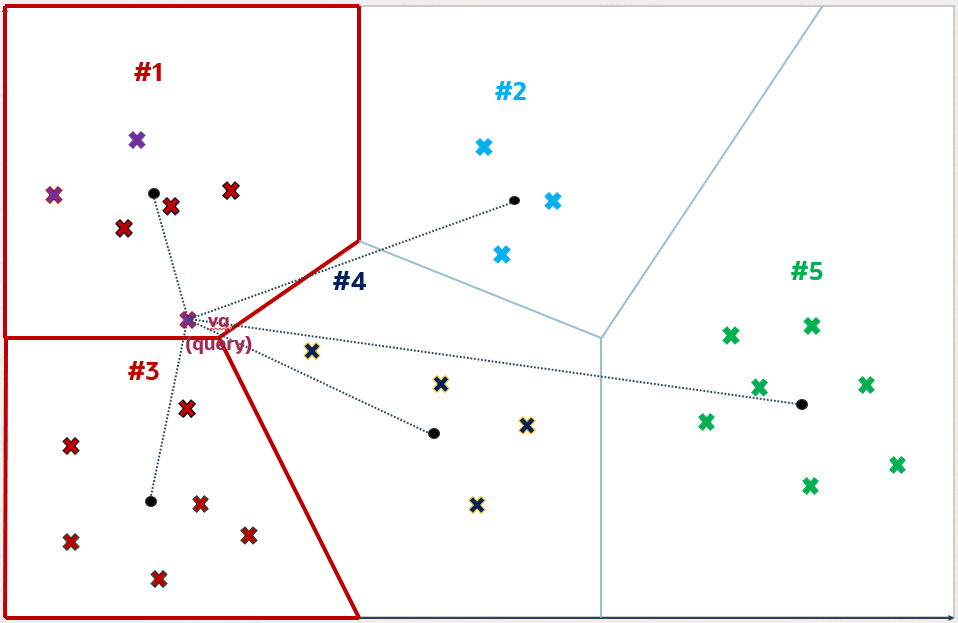
Em seguida, o banco irá selecionar os i centróides mais próximos, que definirão as partições que serão usadas na busca vetorial. O número de i é definido como sendo a raiz quadrada de k. Por exemplo, digamos que a consulta busque os top-5 vetores mais próximos do vetor de referência; nosso i seria 2 (raiz quadrada de 5, aredondada para valor inteiro). O valor de i pode ser definido através do parâmetro NEIGHBOR PARTITION PROBES do comando de criação do índice IVF no Oracle. Para o nosso exemplo, as partições 1 e 3 serão usadas na consulta:
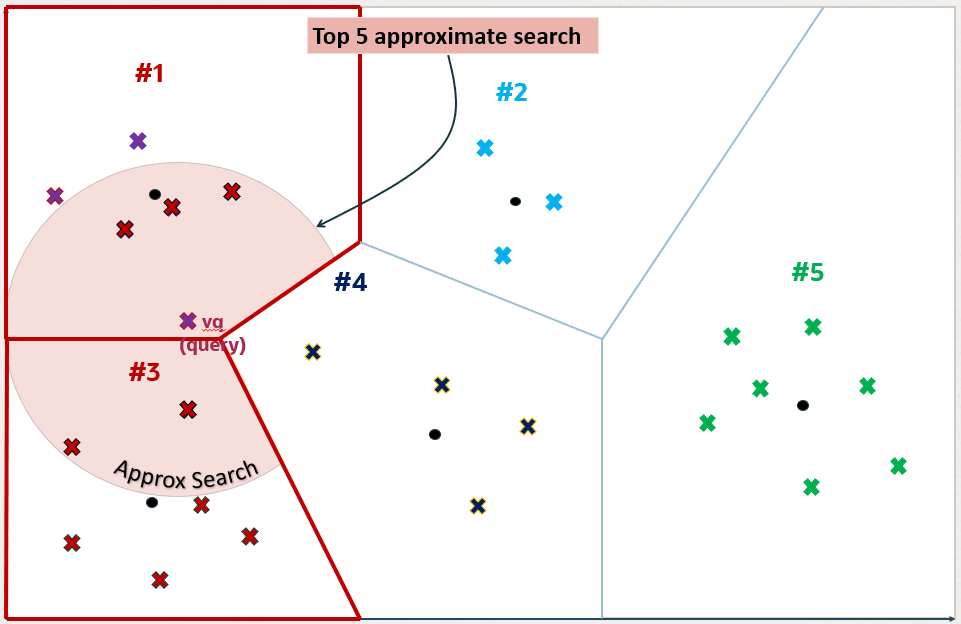
Aqui fica visível que existe um vetor na partição 4 que está entre os top-5 mais próximos em uma Exact Search:

Porém como o centróide dessa partição fica mais distante que os centróides das partições 1 e 3 ele é desconsiderado, e isso é o que causa a perca de precisão do algoritmo. Sendo assim, para esse exemplo, temos uma precisão de 80%:
Conclusão
Agora que entendemos o funcionamento do Inverted File Flat Index, o próximo passo é implementar o índice e ver o plano de execução de uma Approximate Search, visualizando cada um desses passos. E é exatamente o que veremos na parte 2 dessa série.
[…] parte 1 da série de posts sobre os Inverted File Flat (IVF) indexes, falei um pouco sobre o funcionamento […]
[…] Parte 1 […]