
Vector Indexes no Oracle Database: Inverted File Flat (IVF) indexes – Parte 3
Chegamos à parte 3 dessa série de artigos sobre os Inverted File Flat indexes no Oracle Database, e agora o foco é entender como damos manutenção nesse tipo de índice. Se você ainda não leu os artigos anteriores, pode acessá-los aqui:
A precisão importa
Nos artigos anteriores, falei que os índices vetoriais fazem um trade-off entre velocidade e precisão. Para acelerar as consultas vetoriais nós perdemos precisão, mas precisamos ter uma precisão elevada o suficiente para que o modelo LLM que esteja consumindo a informação retornada não alucine, e retorne informacões de baixa qualidade. Bom, isso você já sabe, caso tenha acompanhado essa série de artigos.
O fato novo aqui é que podemos ter perda de precisão das nossas consultas, caso uma massa de dados seja inserida na tabela vetorial, e mude a distribuição dos dados, afetando o índice vetorial.
Para ilustrar, digamos que a nossa massa de dados tenha a seguintes distribuição:
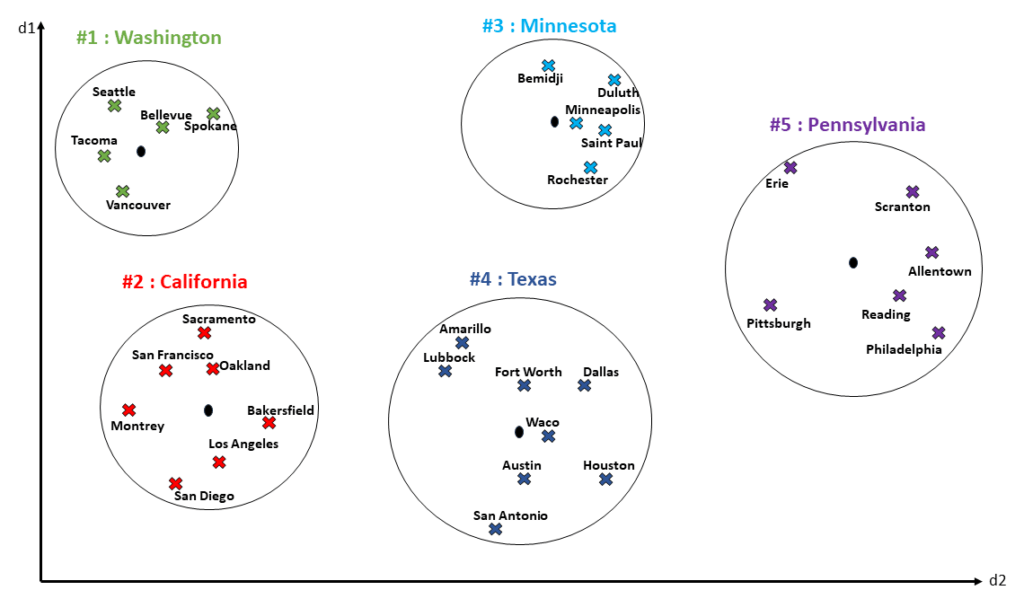
Nesse exemplo, temos cidades, e cada cluster agrupa vetores baseados no estado dessas cidades. Agora, digamos que houve a inserção de novos dados. O seguinte ocorre:
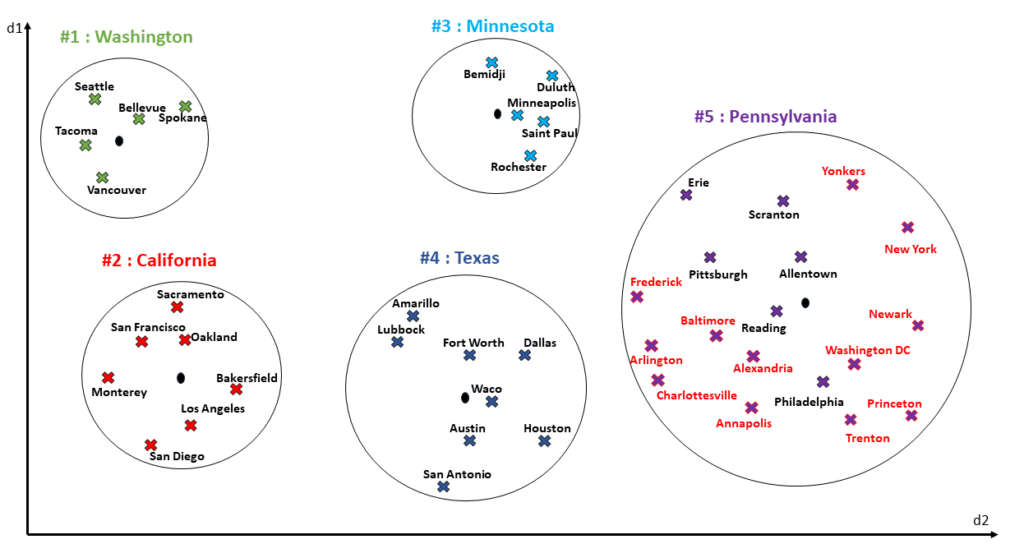
Podemos observar que temos a partição #5 “inchada” (bloated). Isso acontece porque os vetores são inseridos na partição cujo centróide esteja mais próximo desses vetores. Com isso, as consultas top-K podem retornar resultados menos precisos, além de termos uma performance pior quando essas partições maiores precisam ser varridas.
Nesse caso, o ideal é realizar o rebuild do índice. Durante o rebuild, o Oracle irá recalcular a quantidade de centróides necessários para o novo espaço vetorial encontrado, e criar novas partições para comportar os dados. Levando para o nosso exemplo, este seria o espaço vetorial após o rebuild do índice, com duas novas partições existentes, com centróides próprios:
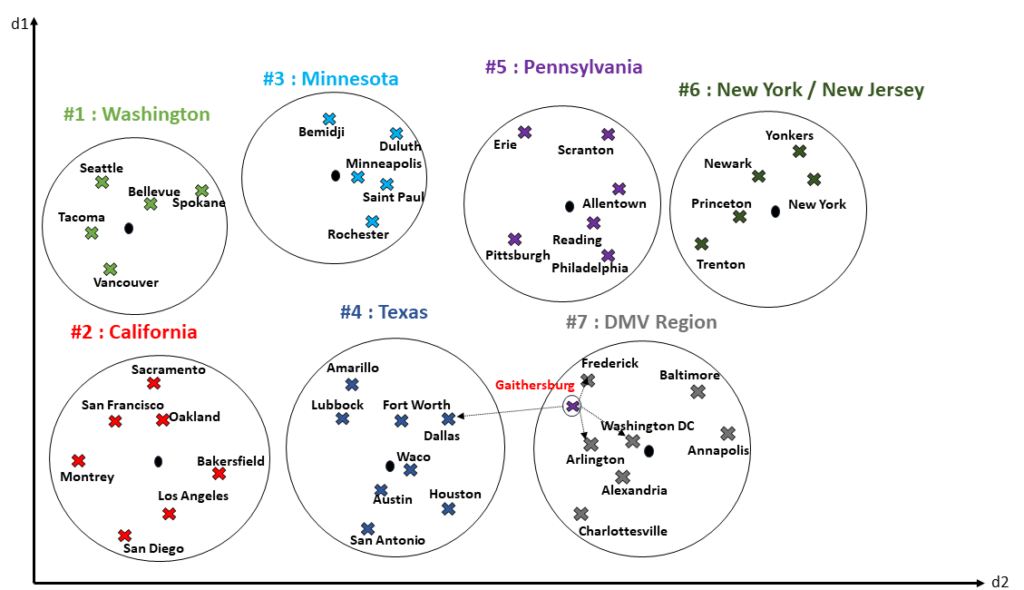
Mensurando a precisão
Agora que entendemos o problema, e temos a solução, a grande questão é: como podemos monitorar a precisão do nosso índice, para saber quando o rebuild se faz necessário?
Para essa monitoria, a versão 26ai do Oracle traz duas funções na package DBMS_VECTOR: INDEX_ACCURACY_QUERY e INDEX_ACCURACY_REPORT.
Aqui vou demonstrar o funcionamento delas, usando um notebook do Google Colab (disponível no meu GitHub). Iniciando pela INDEX_ACCURACY_QUERY, essa função necessita de um vetor para comparação, um valor para top-K e a precisão alvo. Para isso, gerei uma embedding utilizando a OpenAI e a armazenei numa variável vector_arr:
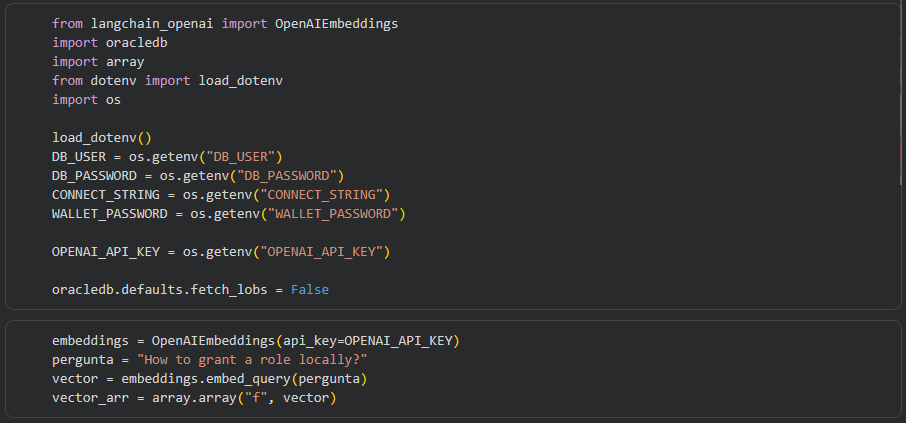
Na sequência, passo essa variável como bind para a função, no parâmetro qv (query vector). Além disso, é preciso especificar o owner e o índice que será avaliado, quantos valores mais próximos devem ser retornados (top_k) e a precisão alvo (target_accuracy), de 90% nesse caso:
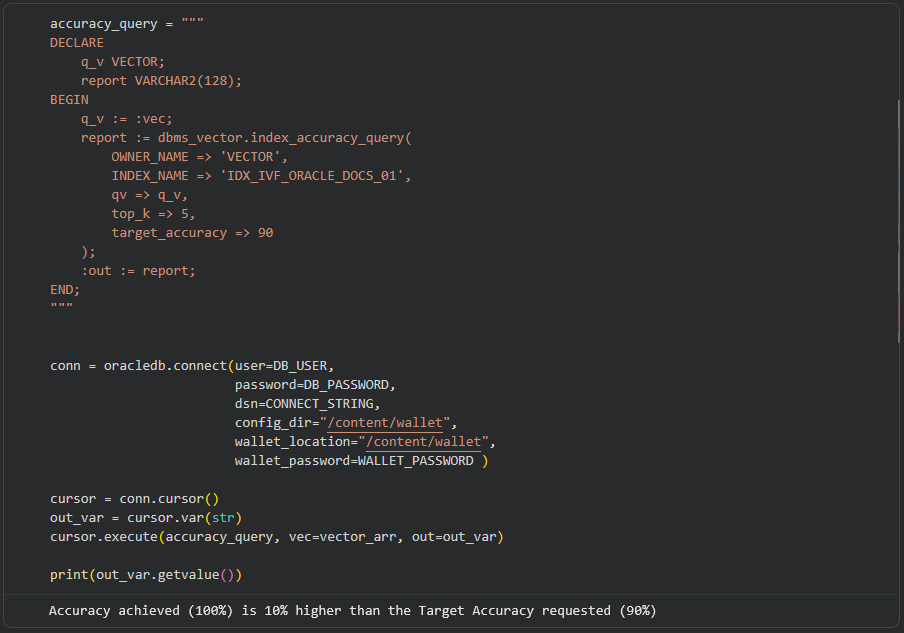
O retorno dessa função é o texto: “Accuracy achieved (100%) is 10% higher than the Target Accuracy requested (90%)“. Por trás dos panos, o que o Oracle faz é executar uma Exact Search, para identificar qual seriam os resultados com 100% de precisão, e na sequência, executa a query novamente, utilizando a Approximate Search através do Inverted File Flat index, e compara os resultados da segunda query com a primeira, calculando assim a precisão.
Essa função é interessante para testes pontuais, para análise da precisão para perguntas específicas feitas à LLM. Agora para um monitoramento contínuo, o ideal é utilizar o INDEX_ACCURACY_REPORT. Essa função recebe o owner e o nome do índice, além dos parâmetros start_time e end_time, para especificar uma janela de tempo na qual a análise deseja ser feita. Se estes dois não forem especificados, a análise será feita com base nas informações das últimas 24 horas.
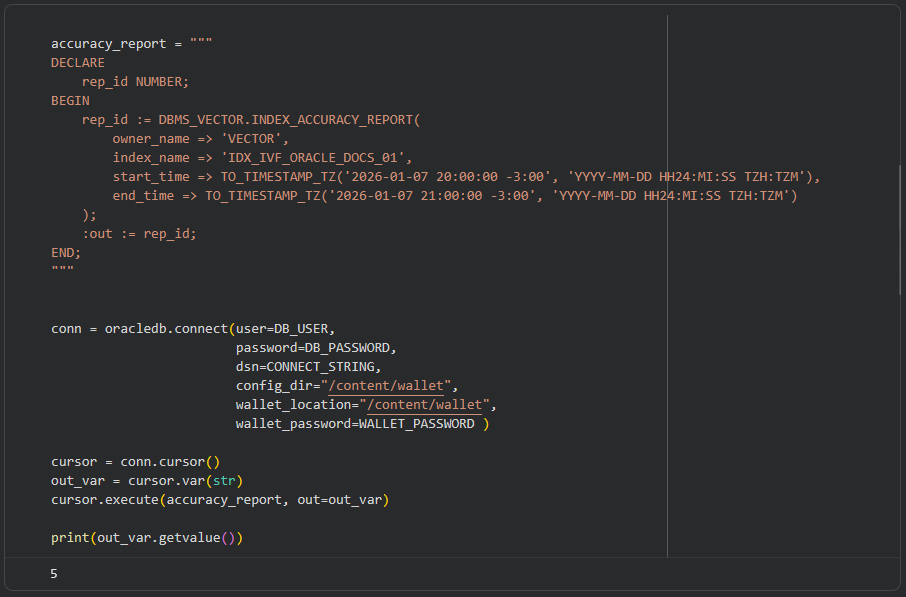
O retorno aqui é um número (neste caso 5), que representa a task_id executada. Com esse valor, podemos consultas os resultados da análise na view DBA_VECTOR_INDEX_ACCURACY_REPORT.
SELECT MIN_TARGET_ACCURACY, MAX_TARGET_ACCURACY, NUM_VECTORS, MIN_ACHIEVED_ACCURACY, MEDIAN_ACHIEVED_ACCURACY, MAX_ACHIEVED_ACCURACY
FROM DBA_VECTOR_INDEX_ACCURACY_REPORT WHERE task_id = 5;
MIN_TARGET_ACCURACY MAX_TARGET_ACCURACY NUM_VECTORS MIN_ACHIEVED_ACCURACY MEDIAN_ACHIEVED_ACCURACY MAX_ACHIEVED_ACCURACY
------------------- ------------------- ----------- --------------------- ------------------------ ---------------------
1 10 2 49 57 65
11 20 3 60 73 83
21 30 3 44 64 84
31 40 2 63 76.5 90
41 50 3 63 81 90
61 70 2 57 68 79
71 80 3 79 87 89
81 90 3 70 71 78
91 100 4 67 79.5 88
Na saída acima, cada linha representar um bucket para as precisões alvo (aquelas definidas na Approximate Search). O exemplo acima eu retirei da documentação, uma vez que no meu ambiente de testes a view estava vazia, provavelmente pelo baixo volume de queries executadas no período de análise.
O ideal aqui é que MIN_ACHIEVED_ACCURACY, MEDIAN_ACHIEVED_ACCURACY e MAX_ACHIEVED_ACCURACY, que representam as precisões mínimas, mediana e máximas alcançadas em cada bucket. Se o valor estiver muito abaixo do esperado, e uma carga recente tenha sido feita na tabela vetorial indexada, isso pode indicar que o índice perdeu a precisão, como exemplificado no ínicio do artigo.
Conclusão
Diferente de índices convencionais, os índices vetoriais necessitam desse acompanhamento mais próximo, pois uma vez que a precisão é comprometida, também será a qualidade das respostas dadas pela LLM. Se pensarmos em um bot de atendimento ao cliente, ou semelhante, um índice com baixa precisão pode afetar a qualidade das respostas, e com isso a satisfação de quem está usando a ferramenta.
Vale citar aqui que a necessidade desse acompanhamento depende muito do comportamento da tabela vetorial. Se os dados que serão inseridos nela são uma base finita de dados e que não sofrerá cargas futuras, você pode checar a precisão de uma maneira menos constante do que em tabelas onde a base de conhecimento cresce ou se modifica constantemente. Em cenários mais dinâmicos, os rebuilds de Inverted File Flat indexes podem ser mais frequentes.
Publicar comentário